R语言操作基础
R语言在统计、计量及科研绘图领域有诸多应用,是强力的科研工具。
为推进对文献的理解,以及入门强大的工具,学习R语言。
由于主要作工具用,并不涉及“编程”,本节仅摘录相关基础知识,以便查阅。
配置为:R4.0.2+Rstudio
1. Rstudio初识
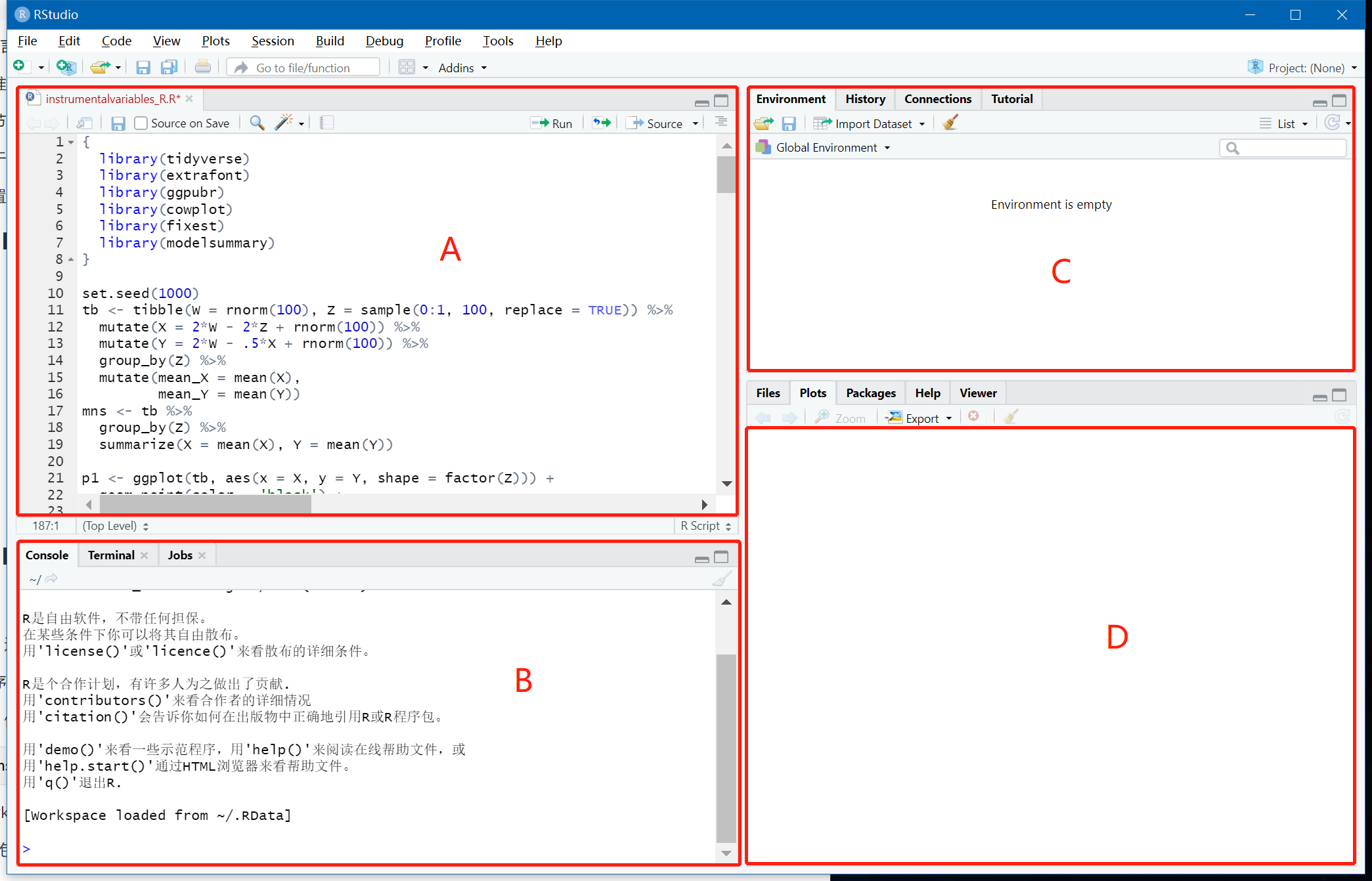
1.1 A区域
这个区域主要负责代码的撰写。刚安装的RStudio,启动时,可能会看不到这个A区域。
而是B区域全部占据了A区域,可点击左上角的【File】→【New File】→【R Script】,即可看见。如果之前打开过R脚本,再打开RStudio会出现之前打开过的R脚本。
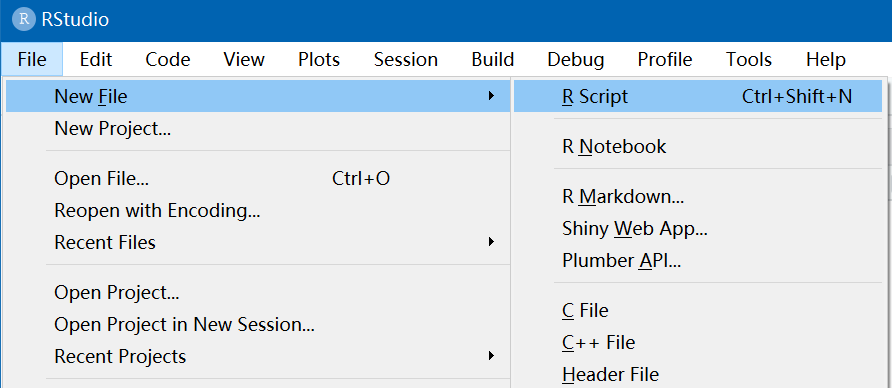
上面步骤将新建一个名为“Untitled1”的R代码文件(后缀名默认为.R)。你可在文件内撰写代码,然后可按快捷键Ctrl + S保存文件。也可点击左上角的【File】→【Save】进行保存。接着会跳出“Save
File”弹出框,然后可将“Untitled1”文件重命名。这里重命名为“test”,然后点“Save”保存文件。文件将保存在你想保存的工作路径下。接着会跳出“Save
File”弹出框,然后可将“Untitled1”文件重命名。这里重命名为“test”,然后点“Save”保存文件。文件将保存在当前工作路径下。
1.2 B区域
这里是执行代码的地方,执行结果也会显示在这里。在A区域输入代码,没执行一行都会在这里显示。也可在这个区域直接输入代码,然后按回车键执行代码,输出结果。在这个区域直接输入代码,执行,和RGUI界面差不多。所有我们就不介绍RGUI。
在A区域输入的代码,可通过点击Run运行光标所在行的代码,点一次运行一行,也可通过【Crtl +Enter】运行。运行的代码会在B区域显示,如果代码有错,也会出现相应的报错提示。B区域随着代码的运行,会越来越多,可通过掃把按钮清空,想要清除Console上的内容,还可按【Ctrl + L】快捷键或者在Console输入cat(')。
1.3 C区域
Environment:是用来记录当前变量的数值,方便查看当前变量的状况。
History:是所有在 Console区内代码执行的历史记录。
Connections:是用来方便连接外部数据库,用得非常少,先不介绍。
1.4 D区域
Files, Plots, Packages, Help, Viewer
Files:这里会显示当前工作路径下的文件,让使用者了解所在的工作路径,这对读写文件非常重要。
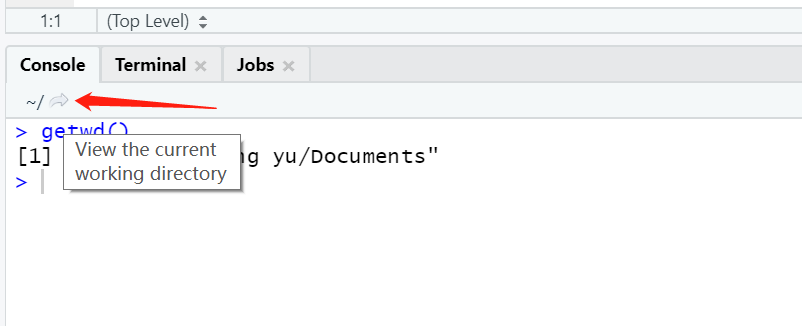
你可通过在Console输入getwd()函数来获取当前工作路径:
如果Files下显示的不是当前工作路径,那是由于没及时更新视图所导致的。可点击Console字符串旁边箭头的来更新,如下图。
Plots:画好的图将在这里显示。
Packages:显示已经安装好了的包,打勾代表已经加载。
安装Package点击Install,然后输入包名;也可在Console中输入相应代码来安装包,比如install.packages('data.table')将安装“data.table”这个包。更新包点Update。
Help:查询函数如何使用,下图是查询read.table。
也可在Console中输入help()函数,()内输入所要查询的函数。比如:help(read.table)。或者直接在Console输入?read.table,如下图。

Viewer:是用来显示本地网页文件,用得比较少。
1.5 RStudio的相关设置
- 切换不同R版本
R允许多个版本共存,比如在电脑上同时安装了2个版本(如下图)。通过RStudio可以很方便在各个R版本间进行切换。
点击【Tools】→【Global Options...】
接着点【General】→【Change...】→【Choose a specific version of R】→选中切换的R版本→【OK】→【OK】;下次启动RStudio后,R将切换到相应版本。这里需要注意的是,在Choose a specific version of R中出现的R版本是已经配置了环境变量的。没有配置环境变量不会自动显示,需要点击Browse去选择你安装的版本。
- 包安装镜像切换
由于网速慢的原因,有时安装包会安装失败。
此时可以通过将包安装切换至中国镜像来解决:点【Tools】→【Global Options...】,接着点【Packages】→【Change...】→【选中一个中国镜像】→【OK】→【OK】。如下图,以后安装包都会通过这个镜像。
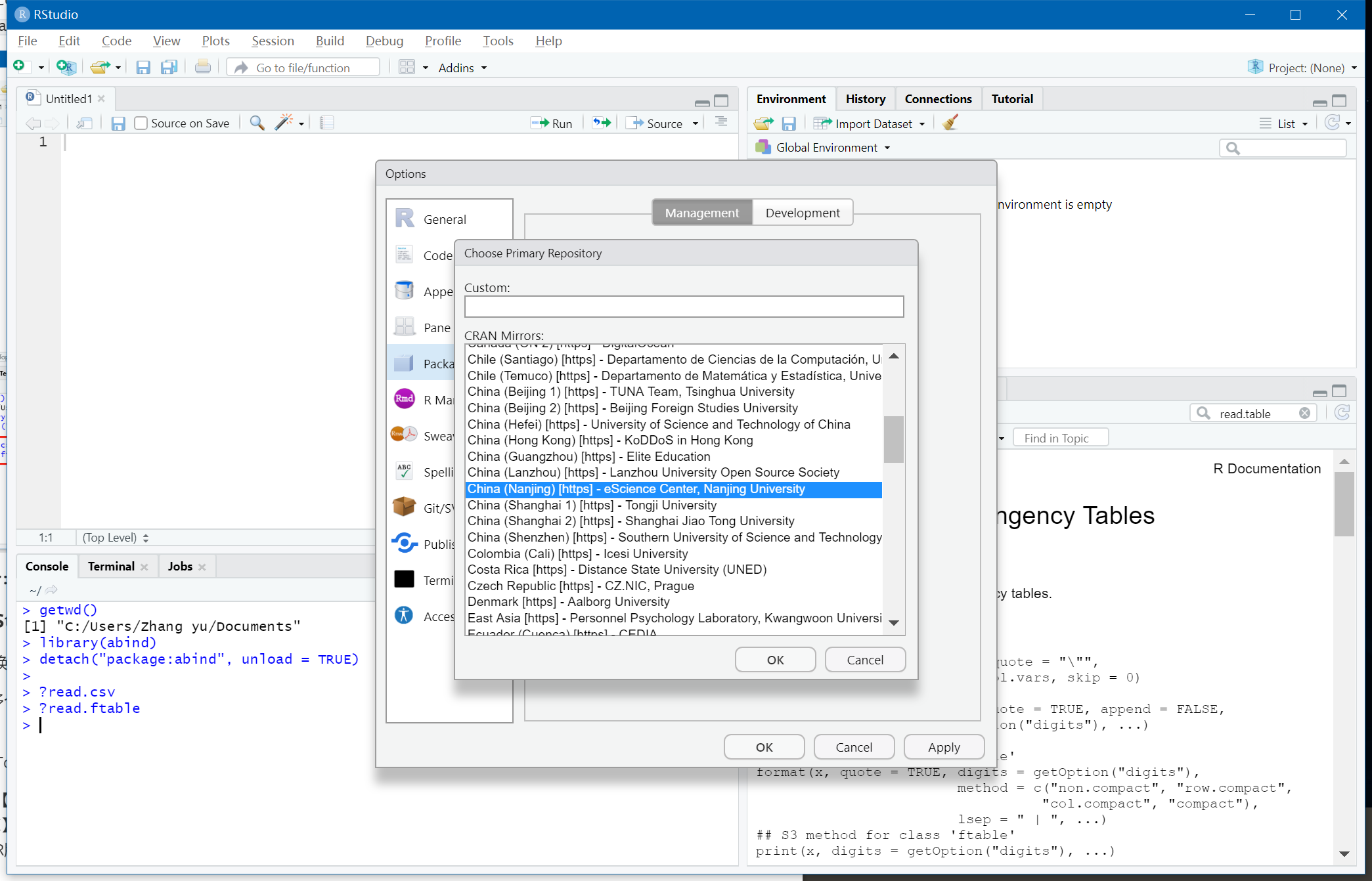
(哈哈,居然还有南大镜像)
- 界面样式的修改
可通过【Tools】→【Global Options...】,接着点【Appearance】进行设置。
- 代码编译格式
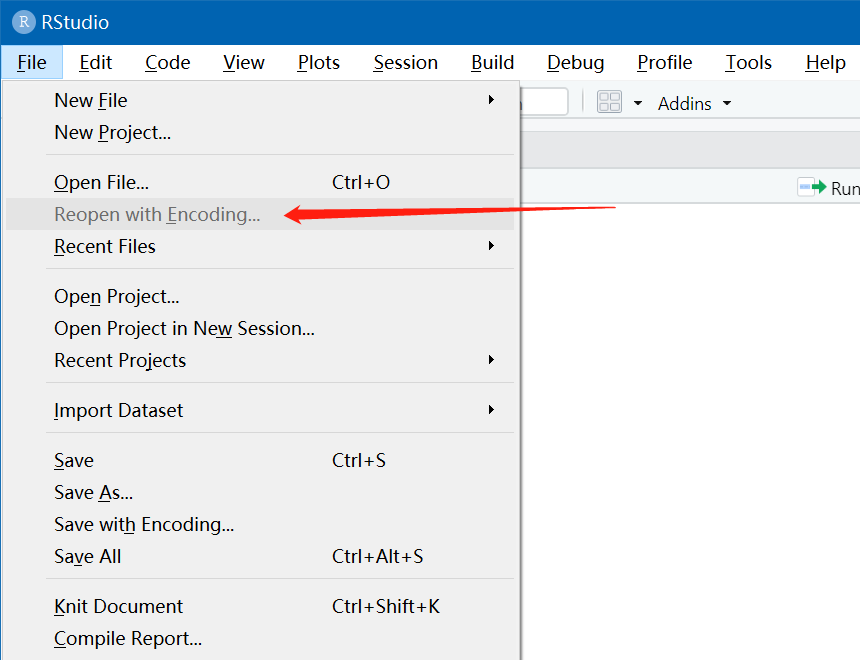
有时候打开别人给你发的代码,里边的中文注释换乱码,可通过【Tools】→【Global Options...】,接着点【Code】→【Saving】进行设置。一般选择UTF-8.
其实也可直接编码重新打开:
2. R语言的包管理与应用
2.1 R包安装
- 通过选择菜单
程序包->安装程序包->在弹出的对话框中,选择你要安装的包,然后确定。
- 使用命令
1 | |
package_name:是指定要安装的包名,请注意大小写。
dir:包安装的路径。默认情况下是安装在..文件夹中的。可以通过本参数来进行修改,来选择安装的文件夹。
- 本地安装
如果你已经下载的相应的包的压缩文件,则可以在本地来进行安装。请注意在windows、unix、macOS操作系统下安装文件的后缀名是不一样的:
1)linux环境编译运行:tar.gz文件
2)windows 环境编译运行 :.zip文件
3)MacOS环境编译运行:.tgz文件
2.2 R包加载
包安装后,如果要使用包的功能。必须先把包加载到内存中(默认情况下,R启动后默认加载基本包),加载包命令:
1 | |
library和require都可以载入包,但二者存在区别。
在一个函数中,如果一个包不存在,执行到library将会停止执行,require则会继续执行。
2.3 查看包的相关信息
1 | |
主要内容包括:例如:包名、作者、版本、更新时间、功能描述、开源协议、存储位置、主要的函数
1 | |
主要内容包括:包的内置所有函数,是更为详细的帮助文档
1 | |
查看当前环境哪些包加载
1 | |
移除包出内存
1 | |
把其它包的数据加载到内存中
1 | |
查看这个包里的包有数据
1 | |
列出所有安装的包
3. R语言语法基础
3.1 基础命令
- ls() list当前工作区内存中的变量
- rm(args) 移除内存变量Remove Object
- history() 查看历史命令清单
- help(“函数”) 打开函数帮助文档
- names(变量) 返回数据集中名字属性
- mode(变量)/class(变量) 返回基本数据类型
- is(变量) 返回变量的基本数据类型和高级数据类型
3.2 变量命令规则
- 字母、数字或者下划线组成
- 变量名称以字母开头,或者点后面不带数字
3.3 运算符
- 算术运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 两个向量相加 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v+t) 它产生以下结果: [1] 10.0 8.5 10.0 |
| − | 从第一个向量减去第二个向量 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v-t) 它产生以下结果: [1] -6.0 2.5 2.0 |
| * | 两个矢量相乘 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v*t) 它产生以下结果: [1] 16.0 16.5 24.0 |
| / | 将第一个向量与第二向量相除 | v <- c( 2,5.5,6) <- c(8, 3, 4) print(v/t) 它产生以下结果: [1] 0.250000 1.833333 1.500000 |
| %% | 得到第一矢量与第二个矢量余数 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v%%t) 它产生以下结果: [1] 2.0 2.5 2.0 |
| %/% | 第一个向量与第二(商)相除的结果 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v%/%t) 它产生以下结果:[1] 0 1 1 |
| ^ | 第一向量提升到第二向量的指数 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v^t) 它产生以下结果: [1] 256.000 166.375 1296.000 |
- 关系运算符
第一向量的每个元素与第二向量的相应元素进行比较。比较的结果是一个布尔值。
| 运算符 | 描述 | 示例 |
|---|---|---|
| > | 检查是否第一向量的每个元素大于第二向量的相应元素。 | v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v>t) 它产生以下结果: [1] FALSE TRUE FALSE FALSE |
| < | 检查是否第一向量的每个元素小于第二向量的相应元素。 | v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v < t) 它产生以下结果: [1] TRUE FALSE TRUE FALSE |
| == | 检查是否第一向量的每个元素等于第二向量的相应元素。 | v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v==t) 它产生以下结果: [1] FALSE FALSE FALSE TRUE |
| <= | 检查是否第一向量的每个元素是小于或等于第二向量的相应的元素。 | v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v<=t) 它产生以下结果: [1] TRUE FALSE TRUE TRUE |
| >= | 检查是否第一向量的每个元素是大于或等于第二向量的相应元素。 | v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v>=t) 它产生以下结果: [1] FALSE TRUE FALSE TRUE |
| != | 检查是否第一向量的每个元素不等于第二向量的相应元素。 | v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v!=t) 它产生以下结果: [1] TRUE TRUE TRUE FALSE |
- 逻辑运算符
它仅适用于一种逻辑,数字或复杂的矢量。所有数值大于1则认为逻辑值为TRUE。
所述第一向量的每个元素与所述第二向量的相应元素进行比较。比较的结果是一个布尔值。
| 运算符 | 描述 | 示例 |
|---|---|---|
| & | 这就是所谓的元素逻辑AND运算符。它结合与第二向量的相应元素的第一向量的每个元素,如果这两个元素都为TRUE则给出一个TRUE。 | v <- c(3,1,TRUE,2+3i) t <- c(4,1,FALSE,2+3i) print(v&t) 它产生以下结果: [1] TRUE TRUE FALSE TRUE |
| \ | 这就是所谓的逐元素逻辑或运算符。它结合与第二向量的相应元素的第一向量的每个元素,如果使用这些元素之一为TRUE则给出一个TRUE。 | v <- c(3,0,TRUE,2+2i) t <- c(4,0,FALSE,2+3i) print(v\t) 它产生以下结果: [1] TRUE FALSE TRUE TRUE |
| ! | 这就是所谓的逻辑非运算符。取向量的每个元素,并给出了相反逻辑值。 | v <- c(3,0,TRUE,2+2i) print(!v) 它产生以下结果: [1] FALSE TRUE FALSE FALSE |
逻辑运算符&&和||考虑矢量仅第一元素并给单个元素作为输出的向量。
| 运算符 | 描述 | 示例 |
|---|---|---|
| && | 所谓的逻辑与运算符。取两个向量的第一元素,仅当两个都为TRUE结果取TRUE。 | v <- c(3,0,TRUE,2+2i) t <- c(1,3,TRUE,2+3i) print(v&&t) 它产生以下结果: [1] TRUE |
| \ | 所谓的逻辑或运算符。取两个向量的第一元素,仅当两个都为TRUE结果为TRUE。 | v <- c(0,0,TRUE,2+2i) t <- c(0,3,TRUE,2+3i) print(v\t) [1] FALSE |
- 赋值运算符
这些操作符是用来分配值到向量。
| 运算符 | 描述 | 示例 |
|---|---|---|
| <- or = or <<- |
叫做左分配 | v1 <- c(3,1,TRUE,2+3i) v2 <<- c(3,1,TRUE,2+3i) v3 = c(3,1,TRUE,2+3i) print(v1) print(v2) print(v3) 它产生以下结果: [1] 3+0i 1+0i 1+0i 2+3i [1] 3+0i 1+0i 1+0i 2+3i [1] 3+0i 1+0i 1+0i 2+3i |
| -> or ->> |
叫做右分配 | c(3,1,TRUE,2+3i) -> v1 c(3,1,TRUE,2+3i) ->> v2 print(v1) print(v2) 它产生以下结果: [1] 3+0i 1+0i 1+0i 2+3i [1] 3+0i 1+0i 1+0i 2+3i |
- 其他运算符
这些操作符被用于为特定的目的,而不是一般的数学或逻辑运算。
| 运算符 | 描述 | 示例 |
|---|---|---|
| : | 冒号运算符。它创建顺序一系列数字的向量 | v <- 2:8 print(v) 它产生以下结果: [1] 2 3 4 5 6 7 8 |
| %in% | 这个操作符用于识别一个元素是否属于(在)一个向量。 | v1 <- 8 v2 <- 12 t <- 1:10 print(v1 %in% t) print(v2 %in% t) 它产生以下结果: [1] TRUE [1] FALSE |
| %*% | 这个操作符是用来乘以它的转置矩阵。 | M = matrix( c(2,6,5,1,10,4), nrow=2,ncol=3,byrow = TRUE) t = M %*% t(M) print(t) 它产生以下结果: [,1] [,2] [1,] 65 82 [2,] 82 117 |
4. 文件的输入与输出
- 从文件中读取数据库获矩阵
read.table()函数是R最基本函数之一,主要用来读取矩形表格数据。
1 | |
各参数的说明如下:
(1)file
file是一个带分隔符的ASCII文本文件。
(2)header
一个表示文件是否在第一行包含了变量的逻辑型变量。
如果header设置为TRUE,则要求第一行要比数据列的数量少一列。
(3)sep
分开数据的分隔符。默认sep=""。
read.table()函数可以将1个或多个空格、tab制表符、换行符或回车符作为分隔符。
(4)quote
用于对有特殊字符的字符串划定接线的字符串,默认值是TRUE(")或单引号。(`)
(5)dec
decimal用于指明数据文件中小数的小数点。
(6)numerals
字符串类型。用于指定文件中的数字转换为双精度数据时丢失精度的情况下如何进行转换。
(7)row.names
保存行名的向量。可以使用此参数以向量的形式给出每行的实际行名。或者要读取的表中包含行名称的列序号或列名字符串。
在数据文件中有行头且首行的字段名比数据列少一个的情况下,数据文件中第1列将被视为行名称。除此情况外,在没有给定row.names参数时,读取的行名将会自动编号。
可以使用row.names = NULL强制行进行编号。
(8)col.names
指定列名的向量。缺省情况下是又"V"加上列序构成,即V1,V2,V3......
Tip:
rownames、colnames是base包中的行名、列名函数;
而row.names、col.names是read.table函数中的行名、参数
(9)as.is
该参数用于确定read.table()函数读取字符型数据时是否转换为因子型变量。当其取值为FALSE时,该函数将把字符型数据转换为因子型数据,取值为TRUE时,仍将其保留为字符型数据。其取值可以是逻辑值向量(必要时可以循环赋值),数值型向量或字符型向量,以控制哪些列不被转换为因子。
注意:可以通过设置参数 colClasses = "character"来阻止所有列转换为因子,包括数值型的列。
(10)na.strings
可选的用于表示缺失值的字符向量。
na.strings=c("-9","?")把-9和?值在读取数据时候转换成NA
(11)colClasses
用于指定列所属类的字符串向量。
(12)nrows
整型数。用于指定从文件中读取的最大行数。负数或其它无效值将会被忽略。
(13)skip
整型数。读取数据时忽略的行数。
(14)check.names
逻辑值。该参数值设置为TRUE时,数据框中的变量名将会被检查,以确保符在语法上是有效的变量名称。
(15)fill
逻辑值。在没有忽略空白行的情况下(即blank.lines.skip=FLASE),且fill设置为TRUE时,如果数据文件中某行的数据少于其他行,则自动添加空白域。
(16)strip.white
逻辑值,默认为FALSE。此参数只在指定了sep参数时有效。当此参数设置为TRUE时,数据文件中没有包围的字符串域的前边和后边的空格将会被去掉。
(17)blank.lines.skip
逻辑值,此参数值设置为TRUE时,数据文件中的空白行将被忽略。默认值为TRUE。
(18)comment.char
字符型。包含单个字符或空字符的向量。代表注释字符的开始字符。可以使用""关闭注释。
(19)allowEscapes
逻辑值。类似“”这种C风格的转义符。如果这种转义符并不是包含在字符串中,该函数可能解释为字段分隔符。
(20)flush
逻辑值。默认值为FALSE。当该参数值设置为TRUE时,则该函数读取完指定列数后将转到下一行。这允许用户在最后一个字段后面添加注释。
(21)stringsAsFactors
逻辑值,标记处字符向量是否需要转化为因子,默认是TRUE。
(22)fileEncoding
字符串类型,指定文件的编码方式。如果指定了该参数,则文本数据按照指定的格式重新编码。
(23)encoding
假定输入字符串的编码方式。
(24)text
字符串类型。当未提供file参数时,则函数可以通过一个文本链接从text中读取数据。
(25)skipNul
逻辑值。是否忽略空值。默认为FALSE。
- 写文件
R 主要用于统计分析,可能读文件比写文件更加常用,但写文件也很重要。读文件用read.table(),写文件就用write.table()。
1 | |
参数说明:
x: 要写入的对象,最好是矩阵或数据框。如果不是,它是试图强迫x到一个数据框。
file: 一个字符串命名文件或编写而打开的一个连接。" "表示输出到控制台。
append: 逻辑。只有当file是一个字符串才相关。
如果TRUE,输出追加到文件
如果FALSE,任何现有文件的名称被摧毁
quote: 一个逻辑值(TRUE或FALSE)或数字向量。如果TRUE,任何字符或因素列将用双引号包围。如果一个数值向量,其元素为引用的列的索引。在这两种情况下,行和列名报价,如果他们被写入。如果FALSE,并没有被引用。
sep: 字段分隔符字符串。每一行x中的值都被这个字符串分隔开。
row.names: 表示x的行名是否与x一起写的逻辑值,或者是写行名的字符向量
col.names: 类似上面。
本篇主要摘录自:
https://zhuanlan.zhihu.com/p/76576574
https://www.cnblogs.com/csguo/p/7293945.html