前文(Handbook
of DID
family )提到,事件研究法现已成为DID策略的标准动作,用于检验平行趋势 和发现外生冲击效应在时间上的变化 ,在此类应用中,事件研究法处于辅助地位。但DID设计本身存在两大缺陷,一是DID策略得到的是平均处理效应(ATE),而现实情况下我们更需要知道外生冲击在不同时段的不同影响,二是DID要求处理效应在冲击后立马显现,但事实上事件的效果往往需要过一段时间才能看出来(比如政策颁布的时点到执行层面落实有很长的间隔、疫苗接种后也不是立即生效)。(事实上DID策略还有很多其他问题,详见前文,在这些情况下,应用事件研究法可能是更好的选择。)
事件研究法为冲击的时间动态提供了丰富的细节(以图形直观展示),很好地弥补了DID的两大缺陷,在未来,事件研究法可能会与DID交换地位,成为处理效应研究的基准结果。
本篇博文摘录了事件研究法近期的进展,并在结尾附上代码,以在实践中学习 为理念,我想通过实际操作,增进自己对事件研究法的掌握。
主要参考资料如下:
1 事件研究法概述
1.1 对事件研究法的直观理解
在前文 模拟数据进行平行趋势检验的代码中,可以发现,事件研究法与DID策略相比,两者回归方程的结构是一样的,但是主要变量由DID的“处理组*处理时点”换成了处理组虚拟变量与时间虚拟变量的所有可能性交互。直观理解就是,事件研究是将DID处理效应的箱子打开,将平均处理效应拆解为一系列“两组-两期”DID组合加权平均,有时事件研究法也被称为动态DID。(仔细想想是不是这样?事件研究法处理效应图中,每一个点都可以理解为一组
2x2 DID)
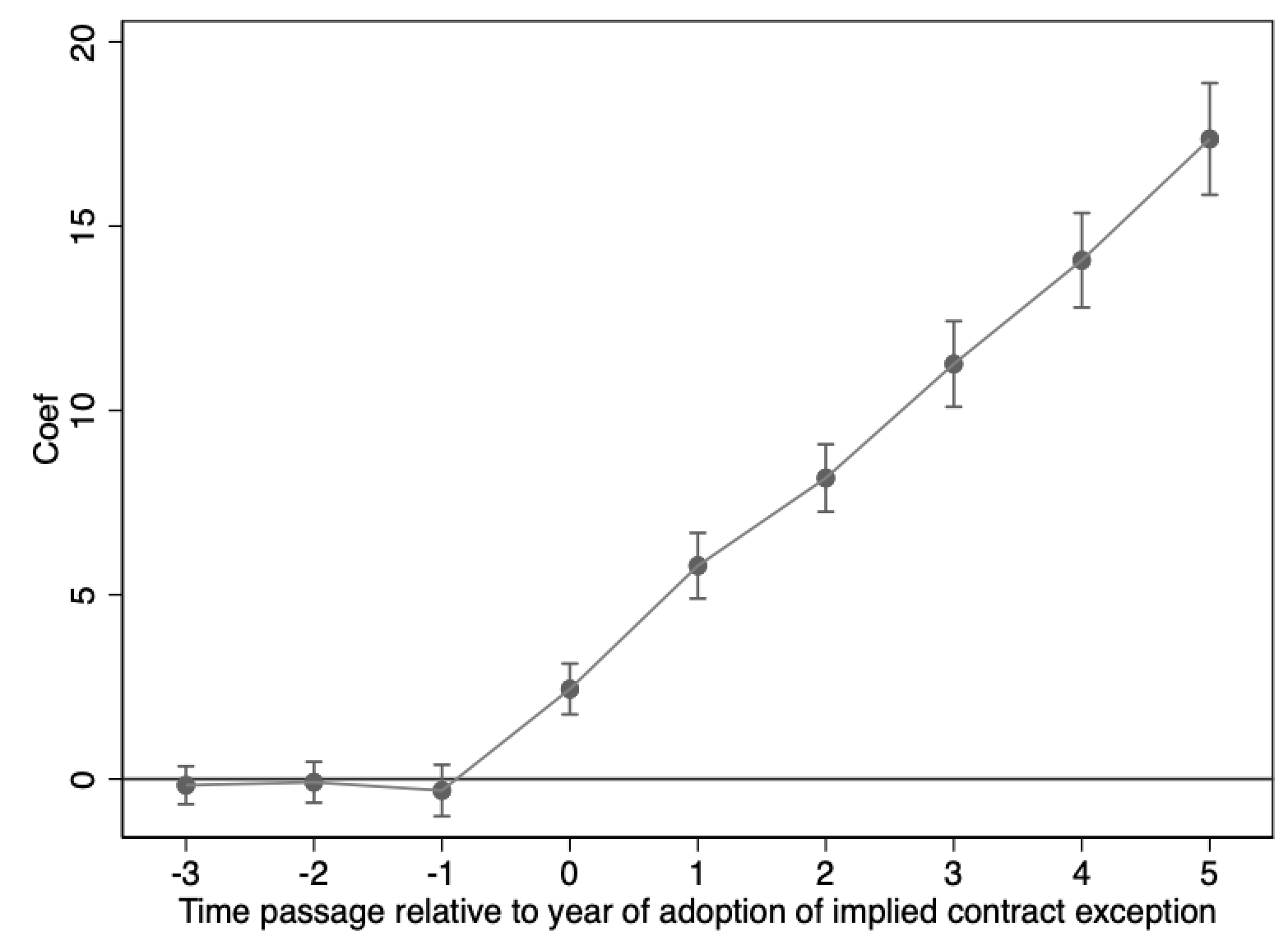
一图胜千言:
image-20231106154603637
⬆️上图展示了前文处理效应随时间变化的模拟数据结果,x轴为处理时点的相对时间,负数表示处理前,正数表示处理后,y轴是回归系数,及处理效应的大小和置信区间。
如果用DID的回归结果,我们能得到处理效应的大小,但是观测不到处理效应随时间的变化。使用事件研究法,我们可以发现在事前不存在处理效应,事后处理效应凸显,且效应的大小随时间增大。更丰富的处理效应,正是我们所关心的。
1.2 结合方程与模拟数据的理解
来看看估计方程 (更换了渲染器,现在复杂公式也可以正常渲染了!):
\[
y_{st} = \alpha + \sum_{j=2}^J\beta_j(\text{Lag}\ j)_{st} +
\sum_{k=1}^K(\text{Lead}\ k)_{st} + \mu_s + \lambda_t +
X'_{st}\Gamma + \epsilon_{st} \quad(1)
\] 式(1),\(y_{st}\) 是第
\(s\) 个个体在第 \(t\) 期的因变量,\(J\) 和 \(K\)
分别表示事前和事后的期数(也称为滞后项和前置项),\(\mu_s\) 和 \(\lambda_t\)
分别为个体固定效应与时间固定效应,我们要看的是前置项的系数。举个例子🌰:研究期为2008年到2017年,事件时点是2013年,那么
\(J\) 就为4,\(J\)
就为5。回归方程代码里,就要把这些年份都考虑进去。(写法很严谨,但见前文代码,操作很简单。)
用JEP论文 里的估计方程理解起来会更方便些(这个公式敲起来老费劲了):
\[
y_{it} =\underbrace{ (\sum_{j\in\{-m,_\cdots,0,_\cdots,n\}
}\gamma_j\cdot D_{i,t-j} ) }_{\mathrm{Event\ Study\ Terms} }\ +
\underbrace{\alpha_i+\delta_t}_{\mathrm{Panel\ Fixed\ Effects} } +
\underbrace{\beta\cdot X_{it} }_{\mathrm{ (Optional)\ Control Variables}
} + \epsilon_{it}\quad(2)
\] 式(2)中的重要系数含义如下:
\(\gamma_j\) :
事件系数,事后的系数能显示了事件处理的动态效果,事前的系数能提供安慰剂检验;\(D_{i,t-j}\) :
事件时间的指示变量。
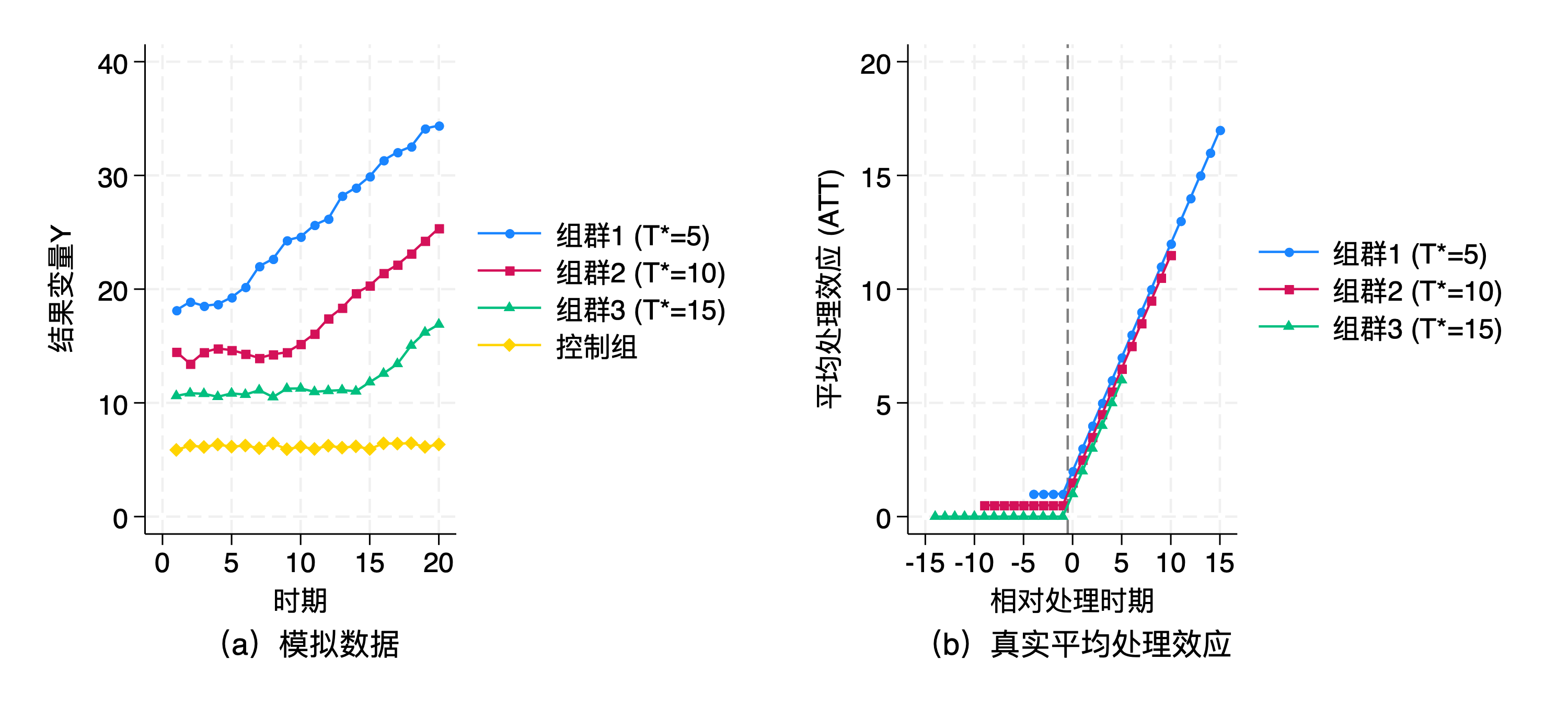
再来看一个模拟数据的例子:
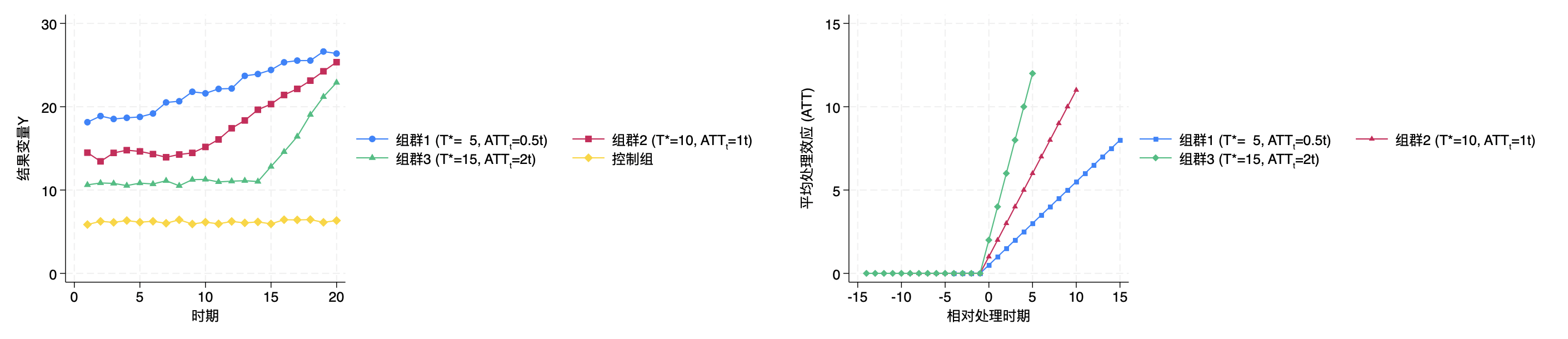
模拟样本中共有 400 个个体,每个个体有 20 期观测值。样本中共包含 4
个组群(Group),分别为 3 组在不同时点接受处理的处理组和 1
组未受处理的控制组,每组均包含 100 个个体。3 组处理组分别在第 5、10、15
期接受处理。处理组个体的处理效应随时间增长,受处理期限每增加 1
期处理效应随之增加 1 单位。(张子尧等,2023)
ES_ATT
试试看此时用DID,算出来的平均处理效应是多少?(实验见代码部分)
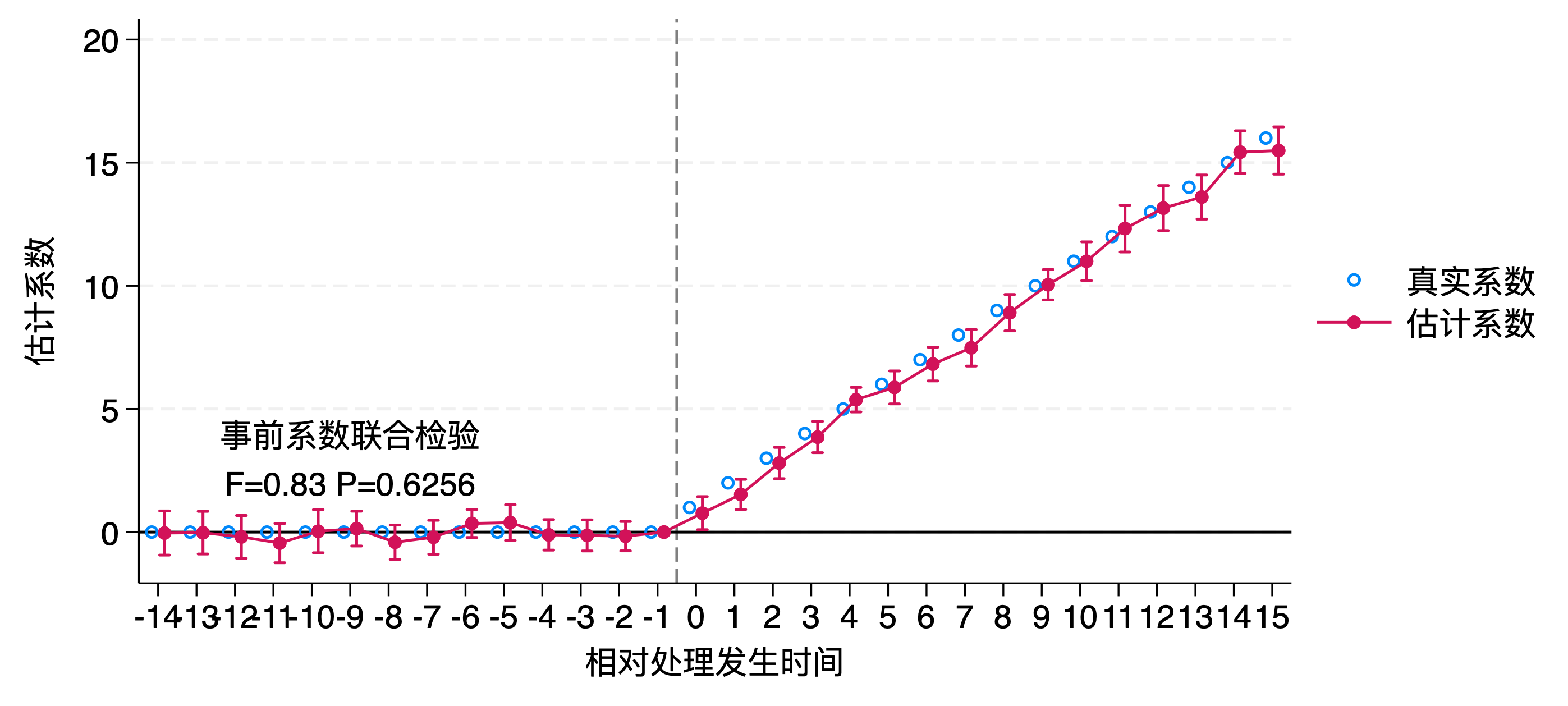
最早的相对处理期是-14期,最晚的相对处理组是15期,每个相对时期的平均处理效应如下(这应该算日历期的结果了?):
image-20231106221142311
1.3 事件研究法的基本假设
指试用TWFE时,事件研究的对象应该满足的假设(即下图a、b的情况):
平行趋势假设
无预期效应假设
同质性处理效应路径假设
image-20231107203952473
2 事件研究法实践中的若干问题
2.1 基期选择
基期是选择一个参照组,作为其他期可比对象,这样才能判断处理效应是不是显著、大小如何。理论上,基期选在处理时点之前的任一期都可,如果在不手动选的话,Stata会默认drop掉最早的一期。
但在实践中,将-1期,即事件发生的前一期作为基期的情况比较普遍,考虑到可能存在预期效应,也可以选择-3期。选择-1期,是现在的标准动作。(选择其他期难免被人怀疑操纵数据或挑选结果)
2.2 对事前平行趋势假设的检验
再强调一遍,平行趋势检验是非常重要的,它是使得潜在结果因果框架里处理组的反事实成立的最重要的条件。
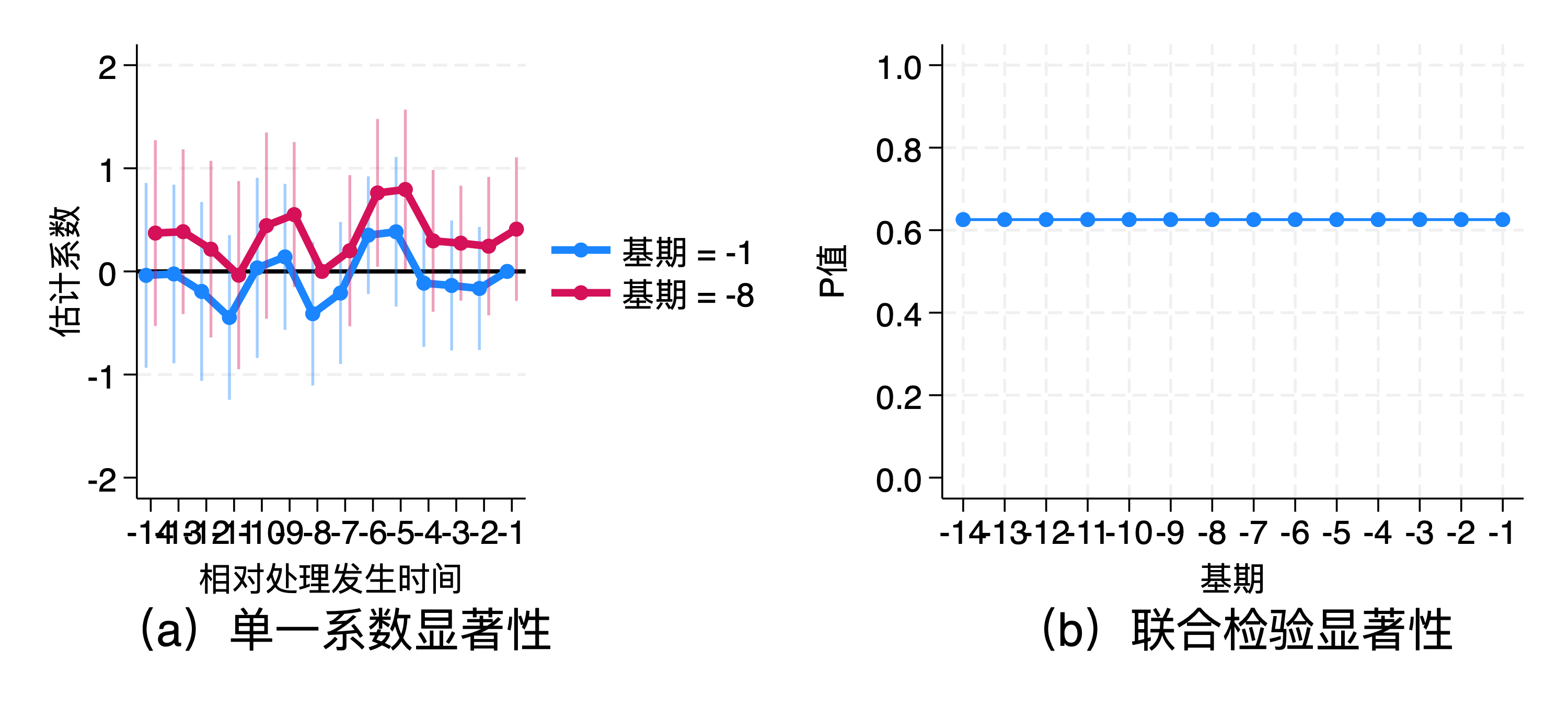
当前的论文中,对平行趋势的检验,就是选择基准期后,观察事前每一期的系数是否为0,如果每一期的系数都不显著,就认为满足事前平行趋势。但这样做有两个问题:
基期的影响很重要,选择不同的基期,系数的结果可能正好相反,基准期会整体上影响每一期系数的显著性;因此,有挑选结果的可能性;
事前平行趋势要求处理前每一期的平均处理效应为 0,其对应的原假设是
\(\mu_{-2}=\mu_{-3}=\cdots=\mu_{-K}=0\)
,而目前的选择基期看系数的检验,检验的其实并不是这个原假设。因此,需要进行系数联合检验而不是关注单一系数的显著性。
联合检验:如F检验,可以用来检查多个系数是否同时等于0。
image-20231106204518638
从(a)看,选择不同的基期,对事前系数的影响较大。
张子尧等(2022)对事前平行趋势检验有如下建议:
第一,必须更加关注事前估计系数是否呈现出明显的时间趋势。个别事前估计系数显著可能仅仅是一种数据噪声导致的偶然现象,然而如果存在明显的事前趋势,可能预示着平行趋势假设不成立,这会直接威胁到事件研究法的识别假设可靠性,可能会导致估计结果产生严重偏误。因此,事前时间趋势(即使不显著)是比个别事前系数显著严重得多的大问题。若估计结果提示可能存在这一类问题,必须对该问题的来源进行详细的分析和讨论,并尽可能地做针对性处理以减轻对估计结果的干扰。
第二,由于事前时间趋势是关注重点,除了某些特殊情况外,必须对估计结果进行图形化以直观判别是否存在事前时间趋势。
第三,检验事前平行趋势应该对事前估计系数做联合检验而不是关注单一系数的显著性。
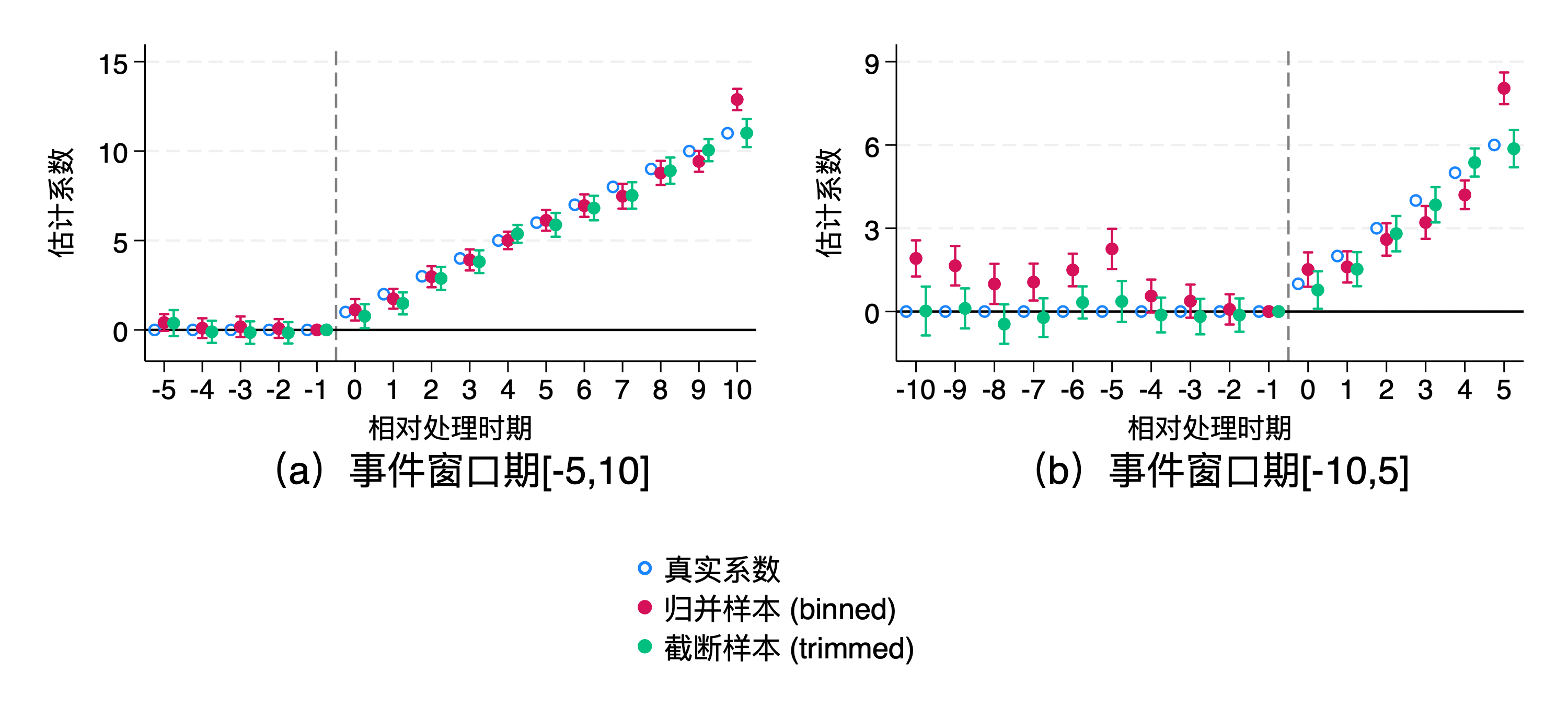
2.3 归并和截断数据
数据归并 (Binning)是指设定一个事件窗口 \([-K,L]\) ,将早于事件窗口的观测值 \((l\le-K)\) 的相对时期重新设定为 \(-K\) 期,将晚于事件窗口的观测值 \(l\ge L\) 的相对时期重新设定为 \(L\) 期。
数据截断 (Trimming)同样是设定一个事件窗口,区别在于将事件窗口外的样本做删除而非归并。
归并数据的优势有二:
一是在样本中没有从未接受处理的控制组时可以避免共线性问题以识别平均处理效应,二是保留了全部样本从而提高了估计效率。在实践中应该避免对处理发生后时期进行归并;若事前平行趋势满足,可以对处理前时期做适当归并。
截断数据的优势在于产生的偏误较小,但有一定的样本选择问题,并降低估计效率。
实践中两种方式都见过。
image-20231106211031460
2.4 正确控制组群异质性时间趋势
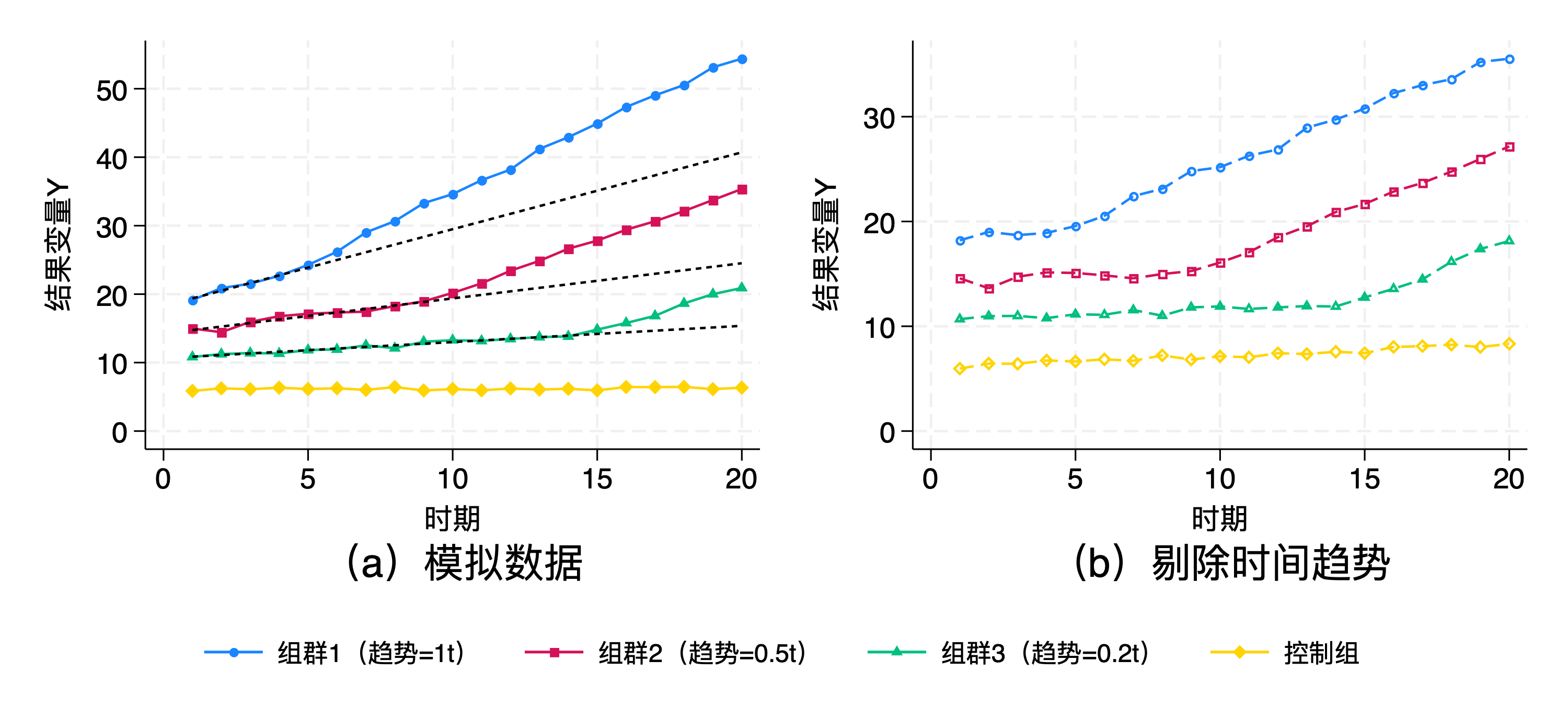
事件研究法的核心识别假设是平行趋势假设。然而,由于涉及处理发生后不可观测的潜在结果,平行趋势假设本身是不可能被直接检验所证实或证伪的。因此,实践中研究者们一方面会检验事前平行趋势是否成立从而间接地为平行趋势假设提供支持,另一方面也考虑尽可能放松平行趋势假设 ,即允许处理组和控制组存在某种确定形式的趋势差异。最常见的是假设组间存在异质性的线性时间趋势,如下图所示,3
个处理组分别存在斜率为 1、0.5、0.2
的线性时间趋势,控制组不存在时间趋势。该数据生成过程显然不满足平行趋势假设,直接使用事件研究法无法得到平均处理效应的一致估计结果。针对这种情况,可以在回归方程的基础上进一步控制组群特定时间趋势:
\[
y_{it} = \alpha_i + \gamma_gf(t) + \sum_{l=-K}^{-2}\mu_l D_{it}^l +
\sum_{l=0}^L\beta_lD_{lt}^l + \epsilon_{it} \quad(3)
\] 式(3)中的 \(f(t)\)
表示时间趋势项的函数形式,可以是线性的,也可以是二次形式的;\(\gamma_g\) 表示时间趋势项的参数,\(g\)
意味着不同组群的时间趋势项存在差异。下图中,控制组的时间趋势斜率 \(\gamma_0 = 0\) ,组群1、2、3
的时间趋势斜率分别为1、0.5 和0.2。
image-20231106211537255
实践中研究者们通常直接回归式(3),认为 \(y_gf(t)\)
可以良好地控制潜在的组间时间趋势差异,从而确保估计系数 \(\mu_l\) 和 \(\beta_l\)
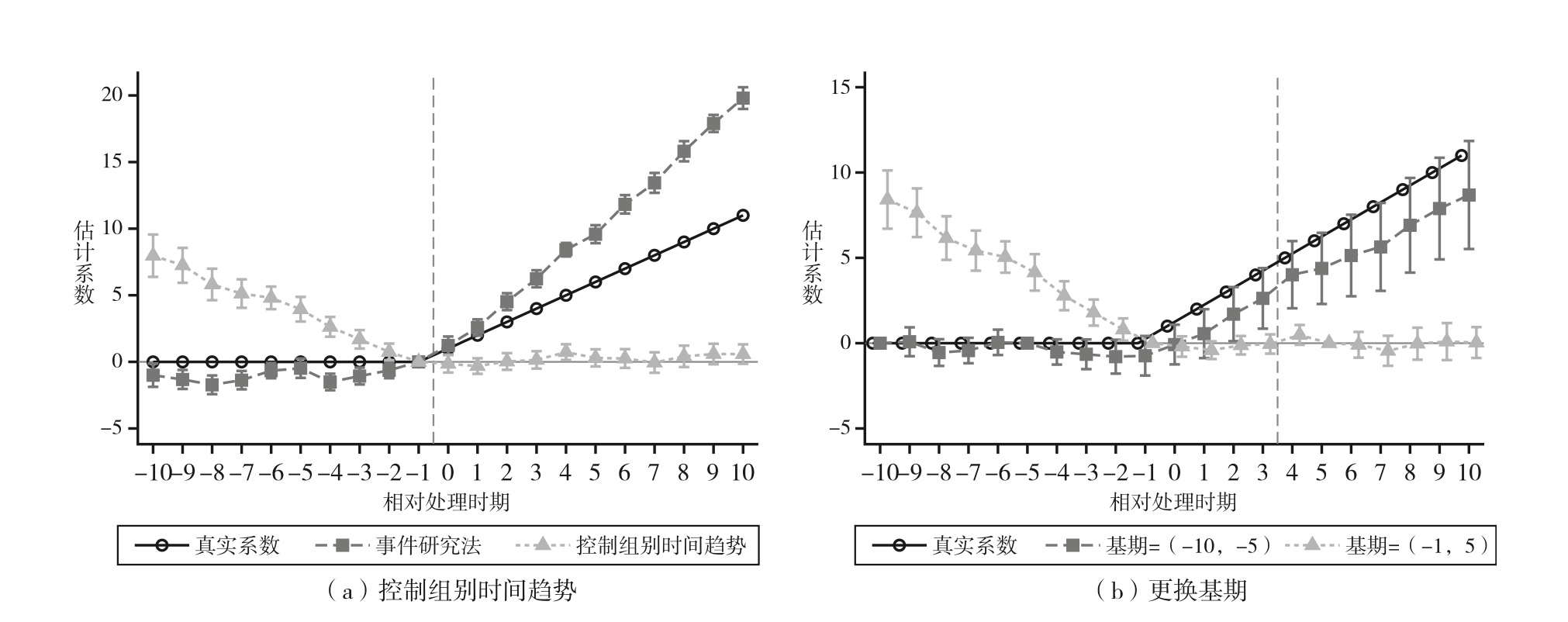
能够一致估计各期平均处理效应。然而事实并非如此 !看例子:
image-20231106214116230
上图中,首先,可以发现由于平行趋势假设不满足,事件研究法无法正确识别处理前和处理后的真实平均处理效应。其次,令人惊讶的是,当控制住组群时间趋势项
\(\gamma_g\times t\)
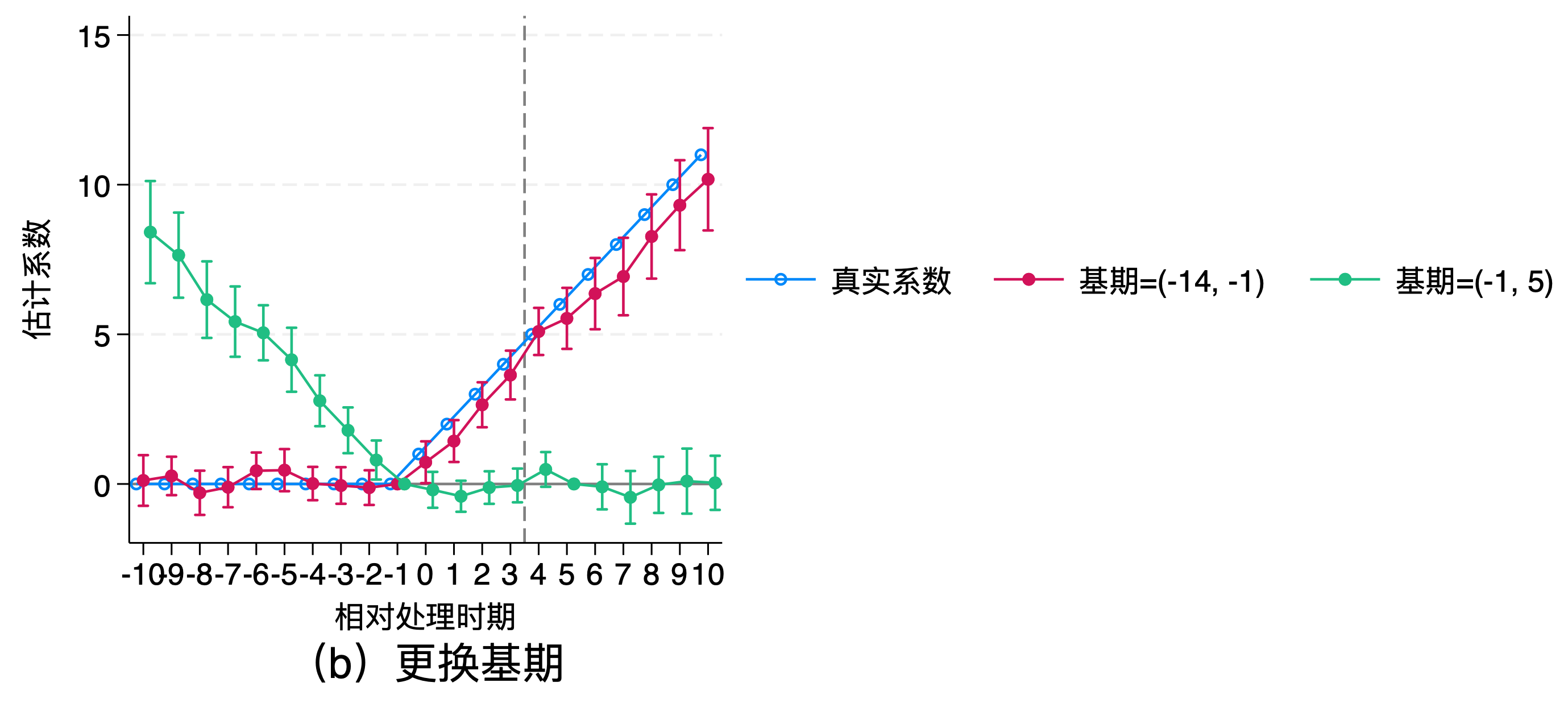
后,事件研究法不仅无法一致估计各期的平均因果效应,甚至会导致更大的估计偏误!并且,基期的选择也会对估计结果有很大影响!
如何处理组群间异质性时间趋势,目前主要有两种方法(我感觉两种方法本质上是一样的):
手动剔除事前趋势的两阶段估计法 :第一阶段使用未接受处理的子样本(控制组和尚未接受处理的处理组)估计组群异质性时间趋势并外推至处理后时期,从结果变量中剔除时间趋势(Detrend)。第二阶段使用剔除事前趋势后的结果变量进行事件研究法估计(Goodman-Bacon,2021;
Dustmann
等,2022)。这种方法背后的逻辑很直观:如果组群时间趋势在处理前和处理后时期保持不变,使用未接受处理的子样本可以正确估计组群时间趋势,经过去趋势处理的结果变量重新满足平行趋势假设,事件研究法能够正确地估计出各期平均处理效应;插补法 :既然问题出在使用全样本无法一致估计组群时间趋势项,那么一个自然的解决思路是使用未接受处理的子样本来正确地识别出组群时间趋势项
\(\gamma_gf(t)\) 以及双向固定效应 \(\alpha_i\) 和 \(\lambda _t\) ,将其从结果变量 \(y_{it}\) 中剔除后再进行回归估计。
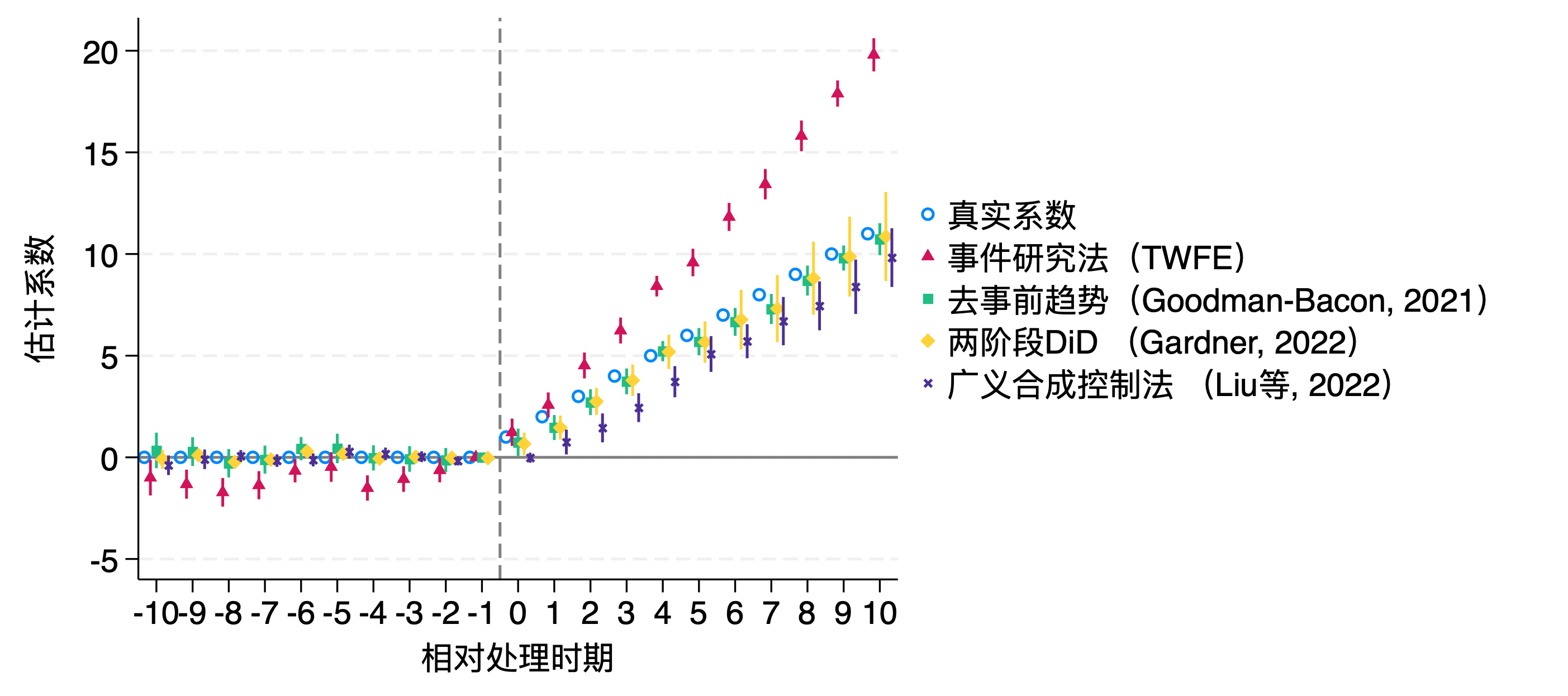
image-20231106220927856
⬆️,这里用两阶段DID和去除事前趋势都比较靠谱。
在实验中,我发现,只要将基期选择为最早的一期和处理前一期,控制时间趋势的话,结果相差不大的,在置信区间内,比如这里,选择-14期和-1期:
image-20231109112514196
可以将时间趋势异质性的组群看成分段函数,起点分别是第一期和处理前一期,基期选择起点即可!
2.5
异质性处理效应条件下的事件研究法
这部分也可以参考Handbook
of DID
family 里的相关内容!还是那些异质性DID的稳健估计量或诊断方法。
2.5.1
异质性处理效应但无组间趋势差异
即满足平行趋势假设和无预期效应假设,但处理效应在组间存在差异,此时使用TWFE得出的处理效应是有偏的。原因是计算处理效应的权重出了问题,有负权重的现象,会把较早接受处理的组当成对照组,即“禁止比较”。(和之前的异质性DID一样,这也是3.2中使用TWFE算出来的处理效应只有2.69的原因)
image-20231112160047110
解决方案主要有(感觉本质是一样的hh):
“组群-时”期平均处理效应估计法:首先估计出组群—时期平均处理效应 \(ATT_{g,l}\)
,然后根据某种权重(等权重或组群规模权重)手动加权求出各相对时期的加权平均处理效应
\(ATT_l\)
。由于在手动加权的过程中人为避免了负权重问题,这类估计量可以修正双向固定效应模型的偏误,正确地估计各时期的平均处理效应;
插补法:使用未受处理的子样本(包括控制组和处理前时期的处理组)估计拟合出处理组个体的反事实结果,而后计算出个体处理效应,最后加总得到各个相对时期的平均处理效应;
堆叠法:通过为每个处理组组群匹配一个由从未接受处理的控制组或尚未接受处理的处理组样本构成的特定控制组,再将匹配好的样本堆叠起来进行回归。
image-20231112163237401
异质性处理效应情形下的事前平行趋势检验
使用全样本会出现参照期和参照对象错误导致的权重错误问题
使用未受处理的子样本即可(包括在剔除接受处理的样本后使用TWFE(如下图),还是异质性稳健估计器(见上图处理时间前部分),都可以)
image-20231112163818038
2.5.2
异质性处理效应+异质性组间趋势
似乎没有什么好的处理办法,作者举了些例子,如处理时点内生选择 :
阿森费尔特沉降(Ashenfelter’s
Dip):Ashenfelter(1978)在评估培训项目对工资的影响时发现职工平均收入在参加培训前有一个明显降低的趋势,后续研究发现这一现象的原因在于失业的工人为了更好地寻找到新工作而更有动机参加职业培训。由于参加职业培训的工人(处理组)与同时期未参加职业培训的工人(控制组)不具有良好的可比性,平行趋势假设很可能并不成立,导致事件研究法无法正确识别因果效应(Heckman
和 Smith,1999)。
另一个常见的例子是离职对员工收入的影响。员工离职有两种可能情形,一种是主动辞职去新的企业工作以获得更高的收入,另一种是被企业强制解雇导致被动失业。显然,不同情形的离职对员工收入的影响存在巨大差异:主动辞职者通常可以获得更高的收入,而被迫失业者收入会大幅度降低。更为严重的问题在于,主动辞职者和被迫失业者(处理组)与持续工作者(控制组)的反事实收入很可能有不同的时间趋势,此时平行趋势假设不再成立。(参加培训这样的事件内生性太强,会有自我选择的情况)
在举个例子,就是下图的数据生成过程:结果变量是个人收入,事件为更换工作,虚线为未更换工作的个人收入反事实潜在结果。从图中可以看到,当个人预期到企业未来经营困难、收入可能会下降时会考虑更换工作;能力越强的员工(事前收入越高)越容易找到新职位,因此会更早更换工作(处理时点靠前),并且新职位的收入也会越高(处理效应更强);
反之,能力较低的员工更难找到新职位,所以更换工作较晚(处理时点靠后)并且新职位的收入更低(处理效应更弱)。由于处理组未受处理的反事实潜在结果与控制组不平行,不满足平行趋势假设。
在这种情形下,无论是基于双向固定效应模型的传统事件研究法还是异质性处理效应稳健估计量都存在估计偏误,都无法 正确估计各期平均处理效应 。
此时的数据情况类似下图:
image-20231112164904412
真实处理效应如下:
image-20231112165018003
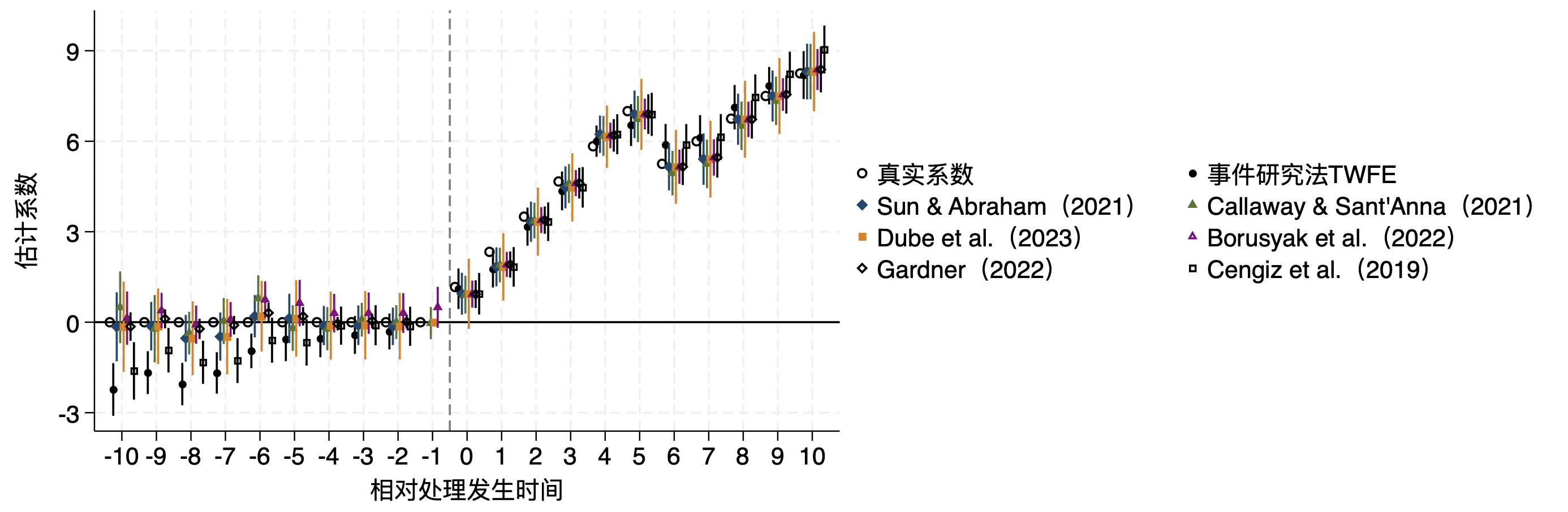
而TWFE和各类稳健估计量都不能很好地准确估计:
image-20231112164748356
怎么知道自己的数据是不是可以有效估计的呢?或者估计结果有没有什么问题?
用TWFE试试看,再用异质性稳健估计量看看,如果两者的结果相差较大,就要注意问题出在哪里!
2.6 其他问题
个体在事件窗口内发生多次事件如何处理
存在影响强度不同的事件该如何处理
事件日期存在空间相关会怎样
等等,可以参考【香樟推文2919】ES,启动!——事件研究法入门指南
3 数据与代码
3.1 数据生成过程
数据生成过程非常重要!!!
一定要理解,难以理解的地方咨询ChatGPT!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 clear allset seed 20230101clear all set obs 400gen id = _nexpand 20bysort id: gen time = _n gen unit_c = runiform(0,10) if time==1egen unit_spec = mean (unit_c), by (id)gen x = runiform(0,1)gen indicator_c = unit_c + 1*x qui sum indicator_c,d scalar threshold1 = r (p25) scalar threshold2 = r (p50)scalar threshold3 = r (p75)egen indicator = mean (indicator_c), by (id)gen treat = 1replace treat = 2 if indicator>threshold1replace treat = 3 if indicator>threshold2replace treat = 4 if indicator>threshold3tab treat, gen (group)gen timing = . replace timing = 5 if treat==2replace timing = 10 if treat==3replace timing = 15 if treat==4gen rel_date = time-timing replace rel_date = 0 if mi (rel_date) gen post = rel_date>=0 gen group_level = 10*group2 + 3*group3 -3*group4 gen group_trend = 0 gen tauit = (1*group2 + 1*group3 + 1*group4)*post *(rel_date+1) gen y0 = group_level + group_trend + unit_spec + runiform(0,10)gen y1 = group_level + group_trend + unit_spec + tauit + runiform(0,10)cap drop ygen D = 0replace D = 1 if rel_date>=0&inlist (treat,2,3,4)gen y = (1-D )*y0 + D *y1 forvalues k = 14(-1)2 {gen relb_`k' = rel_date == -`k' label var relb_`k' "-`k'" gen rel_base = rel_date==-1 label var rel_base "-1" forvalues k = 0/15 {gen relf_`k' = rel_date == `k' label var relf_`k' "`k'" for var relb_* relf_* rel_base: replace X = 0 if group1==1 save simu_data_DGP01, replace set seed 20230101clear all set obs 400gen id = _nexpand 20bysort id: gen time = _n gen unit_c = runiform(0,10) if time==1egen unit_spec = mean (unit_c), by (id)gen x = runiform(0,1)gen indicator_c = unit_c + 1*xqui sum indicator_c,d scalar threshold1 = r (p25)scalar threshold2 = r (p50)scalar threshold3 = r (p75)egen indicator = mean (indicator_c), by (id)gen treat = 1replace treat = 2 if indicator>threshold1replace treat = 3 if indicator>threshold2replace treat = 4 if indicator>threshold3tab treat, gen (group)gen timing = .replace timing = 5 if treat==2replace timing = 10 if treat==3replace timing = 15 if treat==4gen rel_date = time-timingreplace rel_date = 0 if mi (rel_date)gen post = rel_date>=0gen group_level = 10*group2 + 3*group3 -3*group4gen group_trend = (0*group1 + 1*group2 + 0.5*group3 + 0.2*group4)*time gen tauit = (1*group2 + 1*group3 + 1*group4)*post *(1 + rel_date) gen y0 = group_level + group_trend + unit_spec + runiform(0,10)gen y1 = group_level + group_trend + unit_spec + tauit + runiform(0,10)cap drop ygen D = 0replace D = 1 if rel_date>=0&inlist (treat,2,3,4)gen y = (1-D )*y0 + D *y1 forvalues k = 14(-1)2 {gen relb_`k' = rel_date == -`k' label var relb_`k' "-`k'" gen rel_base = rel_date==-1 label var rel_base "-1" forvalues k = 0/15 {gen relf_`k' = rel_date == `k' label var relf_`k' "`k'" for var relb_* relf_* rel_base: replace X = 0 if group1==1 save simu_data_DGP02, replace set seed 20230101clear all set obs 400gen id = _nexpand 20bysort id: gen time = _n gen unit_c = runiform(0,10) if time==1egen unit_spec = mean (unit_c), by (id)gen x = runiform(0,1)gen indicator_c = unit_c + 1*xqui sum indicator_c,d scalar threshold1 = r (p25)scalar threshold2 = r (p50)scalar threshold3 = r (p75)egen indicator = mean (indicator_c), by (id)gen treat = 1replace treat = 2 if indicator>threshold1replace treat = 3 if indicator>threshold2replace treat = 4 if indicator>threshold3tab treat, gen (group)gen timing = .replace timing = 5 if treat==2replace timing = 10 if treat==3replace timing = 15 if treat==4gen rel_date = time-timingreplace rel_date = 0 if mi (rel_date)gen post = rel_date>=0gen group_level = 10*group2 + 3*group3 -3*group4gen group_trend = 0 gen tauit = (0.5*group2 + 1*group3 + 2*group4)*post *(rel_date+1) gen y0 = group_level + group_trend + unit_spec + runiform(0,10)gen y1 = group_level + group_trend + unit_spec + tauit + runiform(0,10)cap drop ygen D = 0replace D = 1 if rel_date>=0&inlist (treat,2,3,4)gen y = (1-D )*y0 + D *y1 gen rel_date_cut = rel_datelocal pre_cut = 14local post_cut = 15replace rel_date_cut = -`pre_cut' if rel_date<-`pre_cut' replace rel_date_cut = `post_cut' if rel_date>`post_cut' tab rel_date_cutforvalues k = `pre_cut' (-1)2 {gen relb_`k' = rel_date_cut == -`k' label var relb_`k' "-`k'" gen rel_base = rel_date_cut==-1label var rel_base "-1" forvalues k = 0/`post_cut' {gen relf_`k' = rel_date_cut == `k' label var relf_`k' "`k'" for var relb_* relf_* rel_base: replace X = 0 if group1==1 save simu_data_DGP03, replace set seed 20230101clear all set obs 400gen id = _nexpand 20bysort id: gen time = _n gen unit_c = runiform(0,10) if time==1egen unit_fe = mean (unit_c), by (id)gen indicator_c = unit_c qui sum indicator_c,d scalar threshold1 = r (p25)scalar threshold2 = r (p50)scalar threshold3 = r (p75)egen indicator = mean (indicator_c), by (id)gen treat = 1replace treat = 2 if indicator>threshold1replace treat = 3 if indicator>threshold2replace treat = 4 if indicator>threshold3tab treat, gen (group)gen timing = .replace timing = 5 if treat==2replace timing = 10 if treat==3replace timing = 15 if treat==4gen rel_date = time-timingreplace rel_date = 0 if mi (rel_date)gen post = rel_date>=0gen group_level = 40*group2 + 25*group3 +10*group4gen group_trend = 0egen X_cf = mean (unit_c), by (treat) gen tauit = (2*group2 + 1*group3 + 0.5*group4)*post *(rel_date+1) gen y0 = group_level + group_trend - 0.1*X_cf*rel_date*post + runiform(0,10)gen y1 = group_level + group_trend - 0.1*X_cf*rel_date*post + tauit + runiform(0,10)cap drop ygen D = 0replace D = 1 if rel_date>=0&inlist (treat,2,3,4)gen y = (1-D )*y0 + D *y1 gen rel_date_cut = rel_datelocal pre_cut = 14local post_cut = 15replace rel_date_cut = -`pre_cut' if rel_date<-`pre_cut' replace rel_date_cut = `post_cut' if rel_date>`post_cut' tab rel_date_cutforvalues k = `pre_cut' (-1)2 {gen relb_`k' = rel_date_cut == -`k' label var relb_`k' "-`k'" gen rel_base = rel_date_cut==-1label var rel_base "-1" forvalues k = 0/`post_cut' {gen relf_`k' = rel_date_cut == `k' label var relf_`k' "`k'" for var relb_* relf_* rel_base: replace X = 0 if group1==1 save simu_data_DGP04, replace
3.2 同质性处理效应路径的情况
即不同组群的冲击时点不同,但效果一致,都随时间线性增加。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 clear alluse simu_data_DGP01, clear preserve collapse (mean ) y, by (treat time) tw (sc y time if treat==2, c(l ) m (o)) sc y time if treat==3, c(l ) m (s)) sc y time if treat==4, c(l ) m (t)) sc y time if treat==1, c(l ) m (d )), ylabel(0(10)40) "(a)模拟数据" , pos(6)) order (1 "组群1 (T*=5)" 2 "组群2 (T*=10)" 3 "组群3 (T*=15)" 4 "控制组" ) $tllgd col(1)) xtitle("时期" ) ytitle("结果变量Y" ) scale(1) name(Homo1)restore preserve collapse (mean ) att=tauit, by (treat rel_date) replace att = att+0.5 if treat==3replace att = att+1 if treat==2tw (sc att rel_date if treat==2, c(l ) m (o)) sc att rel_date if treat==3, c(l ) m (s)) sc att rel_date if treat==4, c(l ) m (t)), xlabel(-15(5)15) "相对处理时期" ) ytitle("平均处理效应 (ATT)" ) "(b)真实平均处理效应" , pos(6)) order (1 "组群1 (T*=5)" 2 "组群2 (T*=10)" 3 "组群3 (T*=15)" ) $tllgd col(1)) scale(1) name(Homo2)restore gr combine Homo1 Homo2, xsize(10) scale(1.5)gr export "figure/ES_ATT.png" , width(3000) replace gr export "figure/ES_ATT.svg" , replace gr save figure/ES_ATT.gph, replace use simu_data_DGP01, clear cluster (id)gl leadall "relb_14 relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lagall "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11 relf_12 relf_13 relf_14 relf_15" testparm $leadall matrix btrue = J (1,30,.)matrix colnames btrue = $leadall $lagall qui forvalues l = 1/14 {matrix btrue[1,`l' ]=0qui forvalues h = 0/15 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +15]=r (mean )matrix list btruematrix (btrue[1]), m (Oh)) (ES_TWFE, recast (connect)), drop (_cons) order (relb* rel_base relf*) omitted baselevel vertical recast (rcap)) yline(0, lc(gs0) lp(solid)) "相对处理发生时间" ) ytitle("估计系数" ) "事前系数联合检验" , place(c)) "F=0.83 P=0.6256" , place(c)) order (2 "真实系数" 4 "估计系数" ) $brlgd col(1)) gr export "figure/ES_TWFE.png" , width(3000) replace gr export "figure/ES_TWFE.svg" , replace gr save figure/ES_TWFE.gph, replace gr drop _all use simu_data_DGP01, clear cluster (id) cluster (id) gl leadall "relb_14 relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" keep ($leadall ) omitted baselevel vertical recast (con) lw(thick) ciopts(recast (rspike) color(%40)) "相对处理发生时间" ) ytitle("估计系数" ) tit("(a)单一系数显著性" , pos(6)) order (2 "基期 = -1" 4 "基期 = -8" ) $brlgd ) scale(1.2) name(PTT1)local leadall "relb_14 relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" tempvar t P gen `t' = _n-15 if _n<=14gen `P' = .forvalues i = 14(-1)2 {local base_period "relb_`i'" local xvar: list leadall - base_period`xvar' o.`base_period' relf_*, a(id time) cluster (id)testparm `leadall' replace `P' = r (p) if `t' ==-`i' `xvar' o.`base_period' relf_*, a(id time) cluster (id)testparm `leadall' replace `P' = r (p) if `t' ==-1sum `P' ,d scatter `P' `t' , c(l ) ylab(0(0.2)1, format (%6.1f)) xlab(-14/-1) "基期" ) ytitle("P值" ) tit("(b)联合检验显著性" , pos(6)) scale(1.2) name(PTT2)gr combine PTT1 PTT2, xsize(10) scale(1.5)gr export "figure/ES_preTest.png" , width(3000) replace gr export "figure/ES_preTest.svg" , replace gr save figure/ES_preTest.gph, replace use simu_data_DGP01, clear cap drop relb_* rel_base relf_*gen rel_date_cut = rel_datelocal pre_cut = 5local post_cut = 10replace rel_date_cut = -`pre_cut' if rel_date<-`pre_cut' replace rel_date_cut = `post_cut' if rel_date>`post_cut' tab rel_date_cutforvalues k = `pre_cut' (-1)2 {gen relb_`k' = rel_date_cut == -`k' label var relb_`k' "-`k'" gen rel_base = rel_date_cut==-1label var rel_base "-1" forvalues k = 0/`post_cut' {gen relf_`k' = rel_date_cut == `k' label var relf_`k' "`k'" for var relb_* relf_* rel_base: replace X = 0 if group1==1 cluster (id) if inrange (rel_date,-5,10), a(id time) cluster (id) gl leadall "relb_5 relb_4 relb_3 relb_2 rel_base" gl lagall "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 " matrix btrue = J (1,16,.)matrix colnames btrue = $leadall $lagall qui forvalues l = 1/5 {matrix btrue[1,`l' ]=0qui forvalues h = 0/10 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +6]=r (mean )matrix list btruematrix (btrue[1]), m (Oh)) ES_bin ES_trim, drop (_cons) order (relb* rel_base relf*) omitted baselevel vertical recast (rcap)) yline(0, lc(gs0) lp(solid)) "相对处理时期" ) ytitle("估计系数" ) order (2 "真实系数" 4 "归并样本 (binned)" 6 "截断样本 (trimmed)" ) $blgd ) "(a)事件窗口期[-5,10]" , pos(6)) name(BT1)use simu_data_DGP01, clear cap drop relb_* rel_base relf_*gen rel_date_cut = rel_datelocal pre_cut = 10local post_cut = 5replace rel_date_cut = -`pre_cut' if rel_date<-`pre_cut' replace rel_date_cut = `post_cut' if rel_date>`post_cut' tab rel_date_cutforvalues k = `pre_cut' (-1)2 {gen relb_`k' = rel_date_cut == -`k' label var relb_`k' "-`k'" gen rel_base = rel_date_cut==-1label var rel_base "-1" forvalues k = 0/`post_cut' {gen relf_`k' = rel_date_cut == `k' label var relf_`k' "`k'" for var relb_* relf_* rel_base: replace X = 0 if group1==1 cluster (id)if inrange (rel_date,-10,5), a(id time) cluster (id)gl leadall "relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lagall "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5" matrix btrue = J (1,16,.)matrix colnames btrue = $leadall $lagall qui forvalues l = 1/10 {matrix btrue[1,`l' ]=0qui forvalues h = 0/5 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +11]=r (mean )matrix list btruematrix (btrue[1]), m (Oh)) ES_bin ES_trim, drop (_cons) order (relb* rel_base relf*) omitted baselevel vertical recast (rcap)) yline(0, lc(gs0) lp(solid)) "相对处理时期" ) ytitle("估计系数" ) order (2 "真实系数" 4 "归并样本 (binned)" 6 "截断样本 (trimmed)" ) $blgd ) "(b)事件窗口期[-10,5]" , pos(6)) name(BT2)gr export "figure/ES_BinTrim.png" , width(3000) replace gr export "figure/ES_BinTrim.svg" , replace gr save figure/ES_BinTrim.gph, replace
3.3 存在组群时间趋势的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 clear alluse simu_data_DGP02, clear cap gr drop GT* preserve collapse (mean ) y, by (treat time)tw (sc y time if treat==2, c(l ) m (o) lp(solid)) sc y time if treat==3, c(l ) m (s) lp(solid)) sc y time if treat==4, c(l ) m (t) lp(solid)) sc y time if treat==1, c(l ) m (d ) lp(solid)) lfit y time if treat==2&time<5, range (1 20) lc(plb1) lp(shortdash)) lfit y time if treat==3&time<10, range (1 20) lc(plr1) lp(shortdash)) lfit y time if treat==4&time<15, range (1 20) lc(plg1) lp(shortdash)) , ylabel(0(10)50) "时期" ) ytitle("结果变量Y" ) order (1 "组群1(趋势=1t)" 2 "组群2(趋势=0.5t)" 3 "组群3(趋势=0.2t)" 4 "控制组" ) $blgd col(2)) "(a)模拟数据" , pos(6)) scale(1.2) name(GT_data1)restore preserve if D ==0, a(id time groupFE=i.treat#c.time) cluster (id) mean (groupFESlope1), by (id) gen grouptrend = time*groupFESlope1 gen y_hat = y - grouptrend collapse (mean ) y_hat, by (treat time)tw (sc y_hat time if treat==2, c(l ) m (oh) lp(dash)) sc y_hat time if treat==3, c(l ) m (sh ) lp(dash)) sc y_hat time if treat==4, c(l ) m (th) lp(dash)) sc y_hat time if treat==1, c(l ) m (dh) lp(dash)), ylabel(0(10)35) "时期" ) ytitle("结果变量Y" ) legend(order (1 "组群1" 2 "组群2 (T*=10, 趋势=0.5t)" 3 "组群3 (T*=15, 趋势=0.2t)" 4 "控制组" ) $blgd row(2)) "(b)剔除时间趋势" , pos(6)) scale(1.2) name(GT_data2)restore gr export "figure/ES_GTdata.png" , width(3000) replace gr export "figure/ES_GTdata.svg" , replace gr save figure/ES_GTdata.gph, replace use simu_data_DGP02, clear cluster (id) cluster (id) gl leadall "relb_14 relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lagall "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11 relf_12 relf_13 relf_14 relf_15" gl lead10 "relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lag10 "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10" matrix btrue = J (1,30,.)matrix colnames btrue = $leadall $lagall qui forvalues l = 1/14 {matrix btrue[1,`l' ]=0qui forvalues h = 0/15 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +15]=r (mean )matrix list btruecap gr drop GT_est*matrix (btrue[1]), msym(Oh)) TWFE TWFE_wtrend, keep ($lead10 $lag10 ) order ($lead10 $lag10 ) omitted baselevel vertical nooffsets recast (connect) ciopts(recast (rcap)) yline(0, lc(gs8) lp(solid)) "相对处理时期" ) ytitle("估计系数" ) order (2 "真实系数" 4 "事件研究法" 6 "控制组别时间趋势" ) $blgd col(3)) "(a)控制组别时间趋势" , pos(6)) scale(1.2) name(GT_est1)est clear cluster (id)cluster (id) matrix (btrue[1]), msym(Oh)) TWFE_wtrend1 TWFE_wtrend2, keep ($lead10 $lag10 ) order ($lead10 $lag10 ) omitted baselevel vertical recast (con) recast (rcap)) yline(0, lc(gs8) lp(solid)) "相对处理时期" ) ytitle("估计系数" ) order (2 "真实系数" 4 "基期=(-10, -5)" 6 "基期=(-1, 5)" ) $blgd col(3)) "(b)更换基期" , pos(6)) scale(1.2) name(GT_est2)gr combine GT_est1 GT_est2, xsize(10) scale(1.3)gr export "figure/ES_GTest.png" , width(3000) replace gr export "figure/ES_GTest.svg" , replace gr save figure/ES_GTest.gph, replace use simu_data_DGP02, clear forvalues i = 1/4{gen group`i' _time = (treat==`i' ) * timeest clear cluster (id) if D ==0, a(id time) cluster (id) keep (group*) r2 se b(4) star(* 0.10 ** 0.05 *** 0.01) use simu_data_DGP02, clear gl leadall "relb_14 relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lagall "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11 relf_12 relf_13 relf_14 relf_15" matrix btrue = J (1,30,.)matrix colnames btrue = $leadall $lagall qui forvalues l = 1/14 {matrix btrue[1,`l' ]=0qui forvalues h = 0/15 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +15]=r (mean )matrix list btruecluster (id) if D ==0, a(id time groupFE=i.treat#c.time) cluster (id)mean (groupFESlope1), by (id)gen grouptrend = time*groupFESlope1gen y_hat = y - grouptrend cluster (id)forvalues i = 1/4{gen group`i' _time = (treat==`i' ) * timeD ) unit(id) time(time) cov(group1_time group2_time group3_time group4_time) method("fe" ) se nboots(100) matrix fect_results = e (ATTs)matrix rownames fect_results = relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 relb_1 relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11matrix fect_b = fect_results[4..24,3] matrix fect_v = fect_results[4..24,4]matrix fect = [fect_b , fect_v]'D ) cluster (id)gl lead10 "relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lag10 "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10" matrix (btrue[1]), msym(Oh) recast (scatter )) m (t)) m (s)) m (d )) matrix (fect[1]), se (2) m (X)), keep ($lead10 $lag10 ) omitted baselevel vertical recast (rspike)) yline(0, lc(gs8) lp(solid)) "相对处理时期" ) ytitle("估计系数" ) order (2 "真实系数" 4 "事件研究法(TWFE)" 6 "去事前趋势(Goodman-Bacon, 2021)" 8 "两阶段DiD (Gardner, 2022)" 10 "广义合成控制法 (Liu等, 2022)" ) $tllgd col(1)) gr export "figure/ES_GTest3.png" , width(3000) replace gr export "figure/ES_GTest3.svg" , replace gr save figure/ES_GTest3.gph, replace
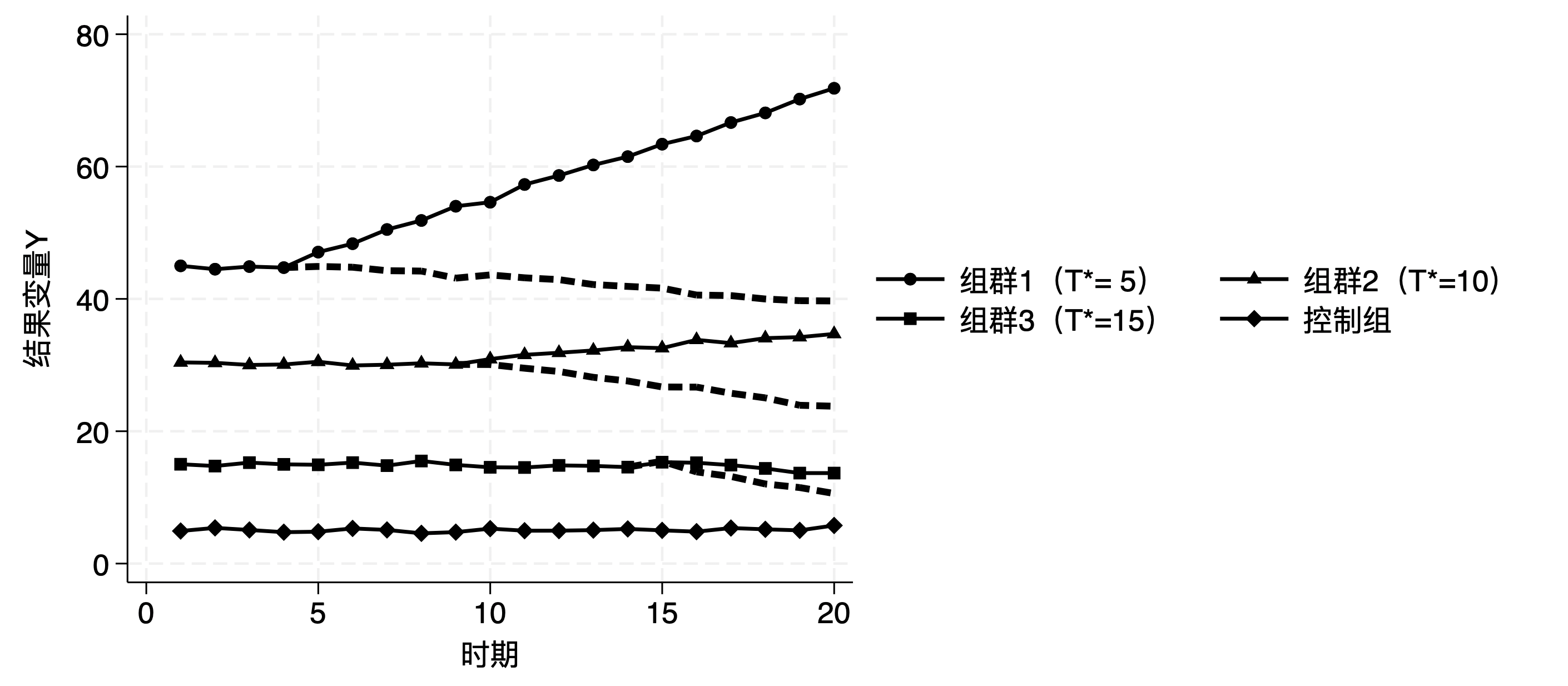
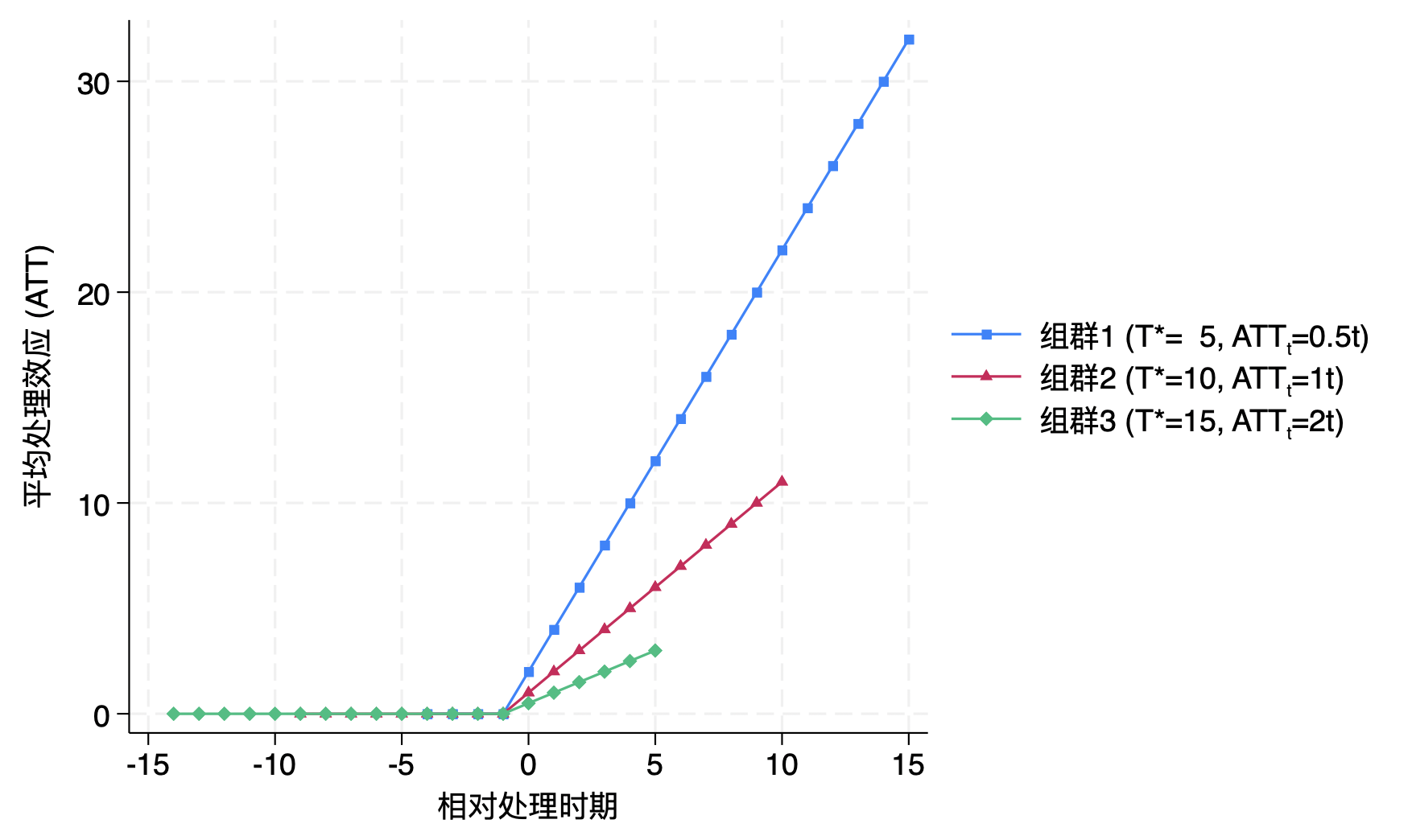
3.4 存在异质性处理效应的情况
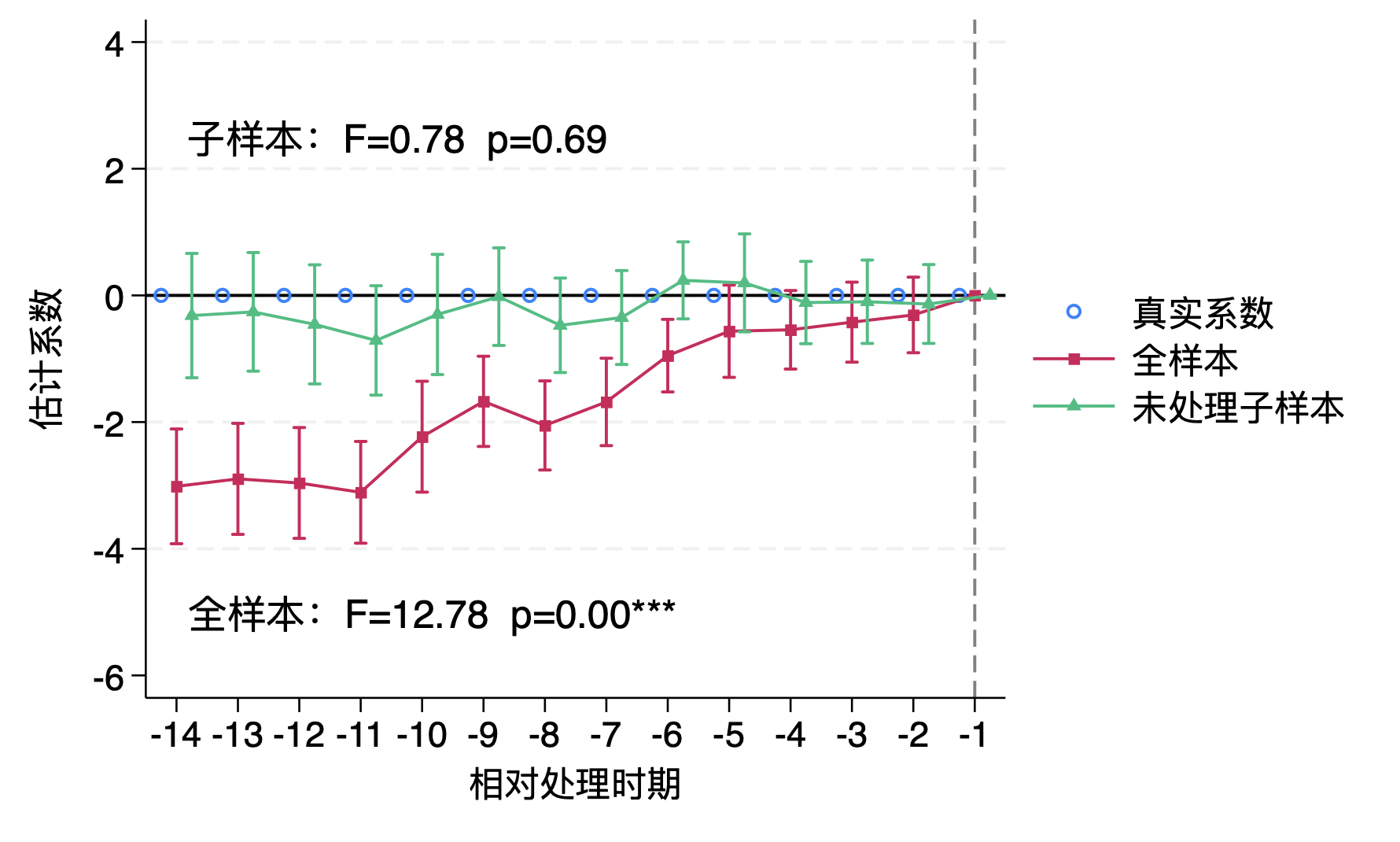
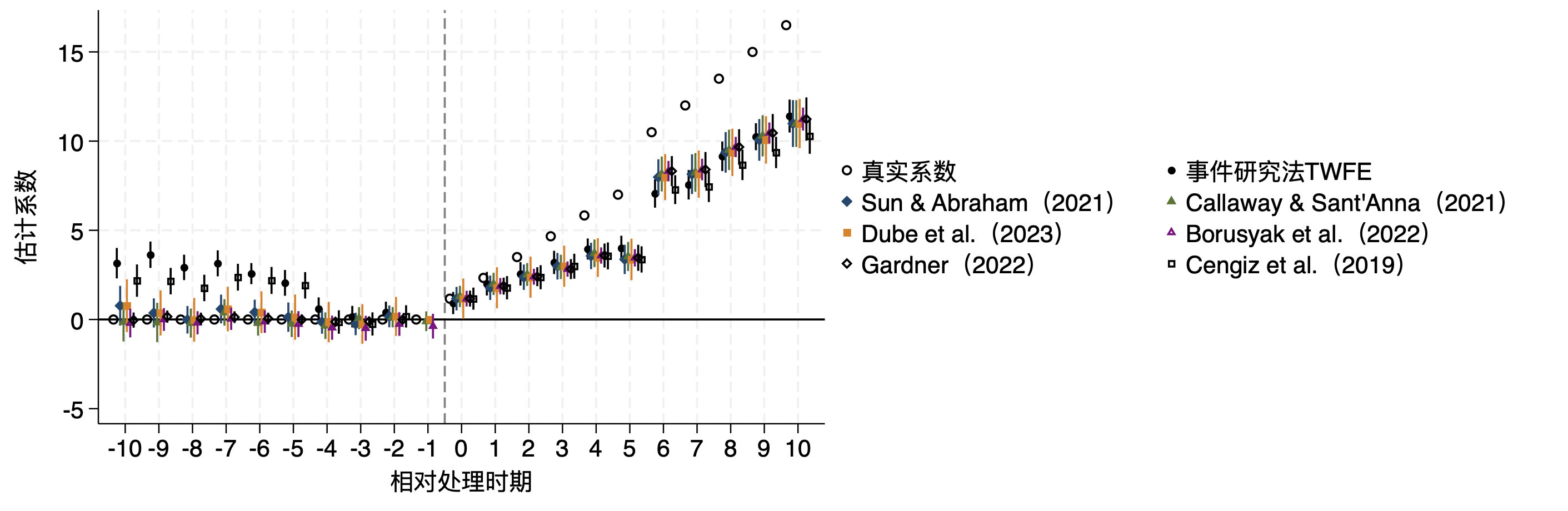
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 clear allgl leadall "relb_14 relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lagall "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11 relf_12 relf_13 relf_14 relf_15" gl lead10 "relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 rel_base" gl lag10 "relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10" use simu_data_DGP03, clear preserve collapse (mean ) y, by (treat time)tw (sc y time if treat==2, c(l ) m (O)) sc y time if treat==3, c(l ) m (S)) sc y time if treat==4, c(l ) m (T)) sc y time if treat==1, c(l ) m (D )), ylabel(0(10)30) order (1 "组群1 (T*= 5, ATT{sub:t}=0.5t)" 2 "组群2 (T*=10, ATT{sub:t}=1t)" 3 "组群3 (T*=15, ATT{sub:t}=2t)" 4 "控制组" ) $blgd col(2)) xtitle("时期" ) ytitle("结果变量Y" ) name(HTdata1)restore preserve collapse (mean ) tauit, by (treat rel_date)tw (sc tauit rel_date if treat==2, c(l ) m (s)) sc tauit rel_date if treat==3, c(l ) m (t)) sc tauit rel_date if treat==4, c(l ) m (d )), xlabel(-15(5)15) "相对处理时期" ) ytitle("平均处理效应 (ATT)" ) order (1 "组群1 (T*= 5, ATT{sub:t}=0.5t)" 2 "组群2 (T*=10, ATT{sub:t}=1t)" 3 "组群3 (T*=15, ATT{sub:t}=2t)" ) $blgd col(2)) name(HTdata2)restore gr combine HTdata1 HTdata2, xsize(10) scale(1.5)use simu_data_DGP03, clear local b_idc "relb_14 relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11 relf_12 relf_13 relf_14 relf_15" `b_idc' , absorb(id time) generate (res_)levelsof timing, local (cohort_list) levelsof rel_date, local (rel_time_list) tempname bb bb_wforeach yy of local cohort_list {foreach rr of local rel_time_list { tempvar cattqui count if timing == `yy' & rel_date == `rr' if r (N ) >0 {qui gen `catt' = (timing == `yy' ) * (rel_date == `rr' )qui regress `catt' res_*, noconsmat `bb_w' = e (b)mat `bb_w' = `yy' , `rr' , `bb_w' matrix `bb' = nullmat (`bb' ) \ `bb_w' matrix colnames `bb' = "timing" "rel_date" `b_idc' matrix ES_weights = `bb' mat list ES_weightsset "weightfiles" , replace matrix (ES_weights), colnames"weightfiles.xlsx" , clear firstrowlocal period "relf_3" keep timing rel_date `period' reshape wide `period' , i (rel_date) j (timing) gr bar `period' 5 `period' 10 `period' 15, over(rel_date) "权重" ) b1tit("相对处理时期" ) order (1 "组群1(T*=5)" 2 "组群2(T*=10)" 3 "组群3(T*=15)" ) col(1) $tllgd ) ysize(3) scale(1.3)gr export "figure/ES_SAweights.png" , width(3000) replace gr export "figure/ES_SAweights.svg" , replace gr save figure/ES_SAweights.gph, replace use simu_data_DGP03, clear matrix btrue = J (1,21,.)matrix colnames btrue = relb10 relb9 relb8 relb7 relb6 relb5 relb4 relb3 relb2 relb1 relf0 relf1 relf2 relf3 relf4 relf5 relf6 relf7 relf8 relf9 relf10qui forvalues l = 1/10 {matrix btrue[1,`l' ]=0qui forvalues h = 0/10 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +11]=r (mean )matrix list btrueest clear cluster (id)gen never = treat==1vce (cluster id) absorb(id time) cohort(timing) control_cohort(never) matrix sa_b = e (b_iw) matrix sa_v = e (V_iw)gen csind = timingreplace csind = 0 if mi (csind)xtset id timecap drop t *_lpdid*gen t = _n-15 if _n<=30gen b_lpdid_fe = .gen se_lpdid_fe = .forval j =14(-1)2 {qui : reghdfe y relb_`j' if (rel_date==-`j' | rel_base==1 & treat!=1) | treat==1, a(id time) cluster (id) qui : replace b_lpdid_fe = _b[relb_`j' ] if t==-`j' qui : replace se_lpdid_fe = _se[relb_`j' ] if t==-`j' forval j =0(1)15 {qui : reghdfe y relf_`j' if (rel_date==`j' | rel_base==1 & treat!=1) | treat==1, a(id time) cluster (id) qui : replace b_lpdid_fe = _b[relf_`j' ] if t==`j' qui : replace se_lpdid_fe = _se[relf_`j' ] if t==`j' replace b_lpdid_fe = 0 if t==-1replace se_lpdid_fe = 0 if t==-1tostring t, replace replace t = "T" + tmkmat b_lpdid_fe, mat (lpdid_b) rownames(t) nomissingmkmat se_lpdid_fe, mat (lpdid_se) rownames(t) nomissingD ) cluster (id)D ) unit(id) time(time) method("fe" ) se nboots(30)matrix fect_results = e (ATTs)matrix rownames fect_results = relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 relb_1 relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11matrix fect_b = fect_results[4..24,3] matrix fect_v = fect_results[4..24,4]stack stack , stub_lag(relf_#) stub_lead(relb_#) plottype(scatter ) ciplottype(rcap) stack , scatter ) ciplottype(rspike) "相对处理发生时间" ) ytitle("估计系数" ) xlabel(-10(1)10) ylabel(-3(3)9) order (1 "真实系数" 2 "事件研究法TWFE" 4 "Sun & Abraham(2021)" "Callaway & Sant'Anna(2021)" 8 "Dube et al.(2023)" 10 "Borusyak et al.(2022)" "Gardner(2022)" 14 "Cengiz et al.(2019)" ) col(2) $tllgd ) d ) color(navy)) lag_ci_opt3(color(navy)) sh ) color(plr2)) lag_ci_opt8(color(plr2)) gr export "figure/ES_HTest1.png" , width(3000) replace gr export "figure/ES_HTest1.svg" , replace gr save figure/ES_HTest1.gph, replace use simu_data_DGP03, clear matrix btrue = J (1,30,.)matrix colnames btrue = $leadall $lagall qui forvalues l = 1/14 {matrix btrue[1,`l' ]=0qui forvalues h = 0/15 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +15]=r (mean )matrix list btruecluster (id)testparm $leadall if D ==0, a(id time) cluster (id)testparm $leadall matrix (btrue[1]), recast (scatter ) msym(Oh) ) (TWFE, m (s) ) (TWFE_pre, m (t)) , keep ($leadall ) omitted baselevel vertical recast (con) ciopts(recast (rcap)) yline(0, lc(gs0) lp(solid)) "相对处理时期" ) ytit("估计系数" ) order (2 "真实系数" 4 "全样本" 6 "未处理子样本" ) $blgd ) "全样本:F=12.78 p=0.00***" , size(medium) placement(e )) "子样本:F=0.78 p=0.69" , size(medium) placement(e )) scale(1.2)gr export "figure/ES_HTpretest.png" , width(3000) replace gr export "figure/ES_HTpretest.svg" , replace gr save figure/ES_HTpretest.gph, replace
3.5
同时存在异质性处理效应与组群时间趋势的情况(估计不准确)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 clear alluse simu_data_DGP04, clear preserve collapse (mean ) y y0 y1, by (treat time rel_date)tw (sc y time if treat==2, color(plb1) lp(solid) lw(medthick) c(l ) m (O)) (line y0 time if treat==2&rel_date>=-1, lc(plb1) lp(dash) lw(thick)) sc y time if treat==3, color(plr1) lp(solid) lw(medthick) c(l ) m (T)) (line y0 time if treat==3&rel_date>=-1, lc(plr1) lp(dash) lw(thick)) sc y time if treat==4, color(plg1) lp(solid) lw(medthick) c(l ) m (S)) (line y0 time if treat==4&rel_date>=-1, lc(plg1) lp(dash) lw(thick)) sc y time if treat==1, color(ply1) lp(solid) lw(medthick) c(l ) m (D )), order (1 "组群1(T*= 5)" 3 "组群2(T*=10)" 5 "组群3(T*=15)" 7 "控制组" ) $blgd col(2)) xtitle("时期" ) ytitle("结果变量Y" ) scale(1.2)restore gr export "figure/ES_HTNPdata.png" , width(3000) replace gr export "figure/ES_HTNPdata.svg" , replace gr save figure/ES_HTNPdata.gph, replace preserve collapse (mean ) tauit, by (treat rel_date)tw (sc tauit rel_date if treat==2, c(l ) m (s)) sc tauit rel_date if treat==3, c(l ) m (t)) sc tauit rel_date if treat==4, c(l ) m (d )), xlabel(-15(5)15) "相对处理时期" ) ytitle("平均处理效应 (ATT)" ) order (1 "组群1 (T*= 5, ATT{sub:t}=0.5t)" 2 "组群2 (T*=10, ATT{sub:t}=1t)" 3 "组群3 (T*=15, ATT{sub:t}=2t)" ) $tllgd col(1)) restore use simu_data_DGP04, clear est clear matrix btrue = J (1,21,.)matrix colnames btrue = relb10 relb9 relb8 relb7 relb6 relb5 relb4 relb3 relb2 relb1 relf0 relf1 relf2 relf3 relf4 relf5 relf6 relf7 relf8 relf9 relf10qui forvalues l = 1/10 {matrix btrue[1,`l' ]=0qui forvalues h = 0/10 {sum tauit if rel_date==`h' &D ==1matrix btrue[1,`h' +11]=r (mean )matrix list btruecluster (id)gen never = treat==1vce (cluster id) absorb(id time) cohort(timing) control_cohort(never)matrix sa_b = e (b_iw) matrix sa_v = e (V_iw)gen csind = timingreplace csind = 0 if mi (csind)xtset id timecap drop t *_lpdid*gen t = _n-15 if _n<=30gen b_lpdid_fe = .gen se_lpdid_fe = .forval j =14(-1)2 {qui : reghdfe y relb_`j' if (rel_date==-`j' | rel_base==1 & treat!=1) | treat==1, a(id time) cluster (id) replace b_lpdid_fe = _b[relb_`j' ] if t==-`j' replace se_lpdid_fe = _se[relb_`j' ] if t==-`j' forval j =0(1)15 {qui : reghdfe y relf_`j' if (rel_date==`j' | rel_base==1 & treat!=1) | treat==1, a(id time) cluster (id) replace b_lpdid_fe = _b[relf_`j' ] if t==`j' replace se_lpdid_fe = _se[relf_`j' ] if t==`j' replace b_lpdid_fe = 0 if t==-1replace se_lpdid_fe = 0 if t==-1tostring t, replace replace t = "T" + tmkmat b_lpdid_fe, mat (lpdid_b) rownames(t) nomissingmkmat se_lpdid_fe, mat (lpdid_se) rownames(t) nomissingD ) cluster (id)D ) unit(id) time(time) method("fe" ) se nboots(30)matrix fect_results = e (ATTs)matrix rownames fect_results = relb_13 relb_12 relb_11 relb_10 relb_9 relb_8 relb_7 relb_6 relb_5 relb_4 relb_3 relb_2 relb_1 relf_0 relf_1 relf_2 relf_3 relf_4 relf_5 relf_6 relf_7 relf_8 relf_9 relf_10 relf_11matrix fect_b = fect_results[4..24,3] matrix fect_v = fect_results[4..24,4]stack stack , stub_lag(relf_#) stub_lead(relb_#) plottype(scatter ) ciplottype(rcap) stack , scatter ) ciplottype(rspike) "相对处理时期" ) ytitle("估计系数" ) xlabel(-10(1)10) ylabel(-5(5)15) order (1 "真实系数" 2 "事件研究法TWFE" 4 "Sun & Abraham(2021)" 6 "Callaway & Sant'Anna(2021)" 8 "Dube et al.(2023)" 10 "Borusyak et al.(2022)" "Gardner(2022)" 14 "Cengiz et al.(2019)" ) col(2) $tllgd ) d ) color(navy)) lag_ci_opt3(color(navy)) sh ) color(plr2)) lag_ci_opt8(color(plr2)) gr export "figure/ES_HTNPest.png" , width(3000) replace gr export "figure/ES_HTNPest.svg" , replace gr save figure/ES_HTNPest.gph, replace
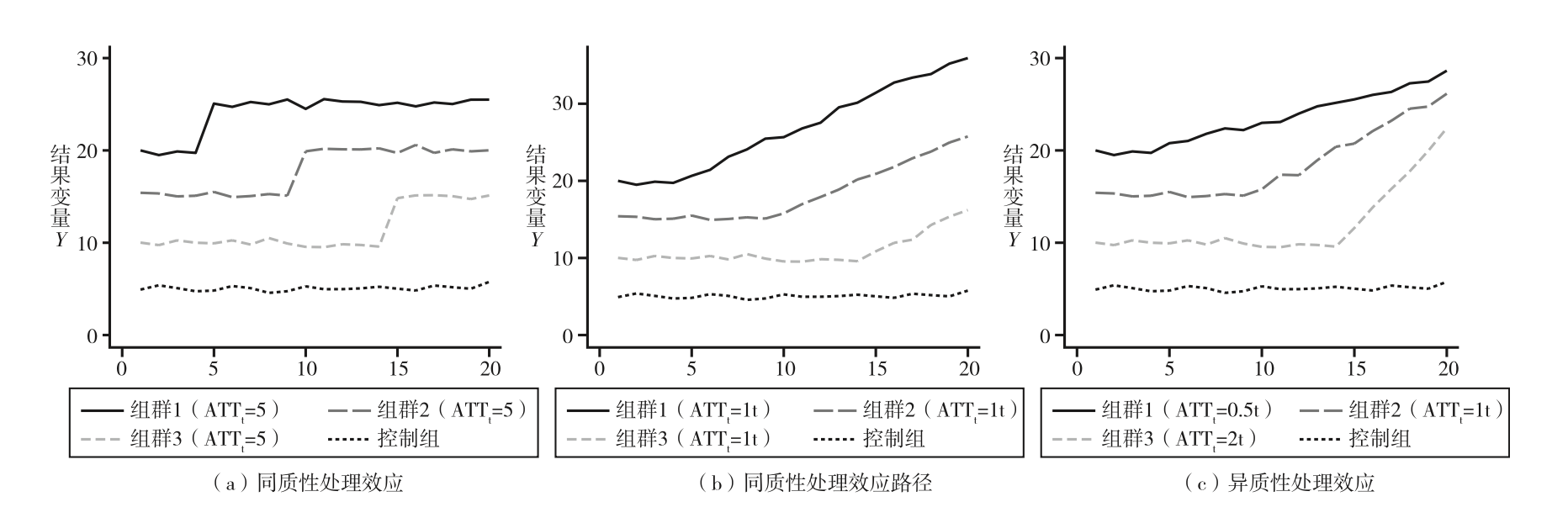
3.6 原文图1和图4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 cd "$root" clear alluse Currie_2020, clear tw (line DD year, lw(thick)) (line ES year, lw(thick)), format (%6.2f)) order (1 "双重差分法" 2 "事件研究法" )) "" ) ytitle("占比" ) subtitle("(a)英文经济学五大刊" , pos(6)) scale(1.2) name(top5)use cntop, clear keep if year>=2004gen DD_share = dd/total gen ES_share = es/total gen ESPT_share = espt/total two (line DD_share year, lw(thick)) line ES_share year, lw(thick)) line ESPT_share year, lw(thick) lp(shortdash)), format (%6.2f)) order (1 "双重差分法" 2 "事件研究法" 3 "事件研究法+平行趋势" ) size(medsmall)) "" ) ytitle("占比" ) subtitle("(b)中文权威期刊" , pos(6)) scale(1.2) name(cntop)gr export "figure/topshare.png" , width(3000) replace gr export "figure/topshare.svg" , replace set seed 20230101clear all set obs 400gen id = _nexpand 20bysort id: gen time = _n gen unit_c = runiform(0,10) if time==1egen unit_fe = mean (unit_c), by (id)gen indicator_c = unit_c qui sum indicator_c,d scalar threshold1 = r (p25)scalar threshold2 = r (p50)scalar threshold3 = r (p75)egen indicator = mean (indicator_c), by (id)gen treat = 1replace treat = 2 if indicator>threshold1replace treat = 3 if indicator>threshold2replace treat = 4 if indicator>threshold3tab treat, gen (group)gen timing = .replace timing = 5 if treat==2replace timing = 10 if treat==3replace timing = 15 if treat==4gen rel_date = time-timingreplace rel_date = 0 if mi (rel_date)gen post = rel_date>=0gen group_level = 15*group2 + 10*group3 +5*group4gen group_trend = 0egen X_cf = mean (unit_c), by (treat)gen y0 = group_level + group_trend + runiform(0,10)gen y11 = group_level + group_trend + (5*group2 + 5*group3 + 5*group4)*post + runiform(0,10) gen y12 = group_level + group_trend + (1*group2 + 1*group3 + 1*group4)*post *(rel_date+1) + runiform(0,10) gen y13 = group_level + group_trend + (0.5*group2 + 1*group3 + 2*group4)*post *(rel_date+1) + runiform(0,10) cap drop ygen D = 0replace D = 1 if rel_date>=0&inlist (treat,2,3,4)gen y1 = (1-D )*y0 + D *y11gen y2 = (1-D )*y0 + D *y12gen y3 = (1-D )*y0 + D *y13preserve collapse (mean ) y1 y2 y3 y0, by (treat time)tw (line y1 time if treat==2, lw(thick)) line y1 time if treat==3, lw(thick)) line y1 time if treat==4, lw(thick)) line y1 time if treat==1, lw(thick)), ylabel(0(10)30) order (1 "组群1(ATT{sub:t}=5)" 2 "组群2(ATT{sub:t}=5)" 3 "组群3(ATT{sub:t}=5)" 4 "控制组" ) $blgd col(2)) xtitle("" ) ytitle("结果变量Y" ) "(a)同质性处理效应" , pos(6)) name(TEA1)restore preserve collapse (mean ) y1 y2 y3 y0, by (treat time)tw (line y2 time if treat==2, lw(thick)) line y2 time if treat==3, lw(thick)) line y2 time if treat==4, lw(thick)) line y2 time if treat==1, lw(thick)), ylabel(0(10)30) order (1 "组群1(ATT{sub:t}=1t)" 2 "组群2(ATT{sub:t}=1t)" 3 "组群3(ATT{sub:t}=1t)" 4 "控制组" ) $blgd col(2)) xtitle("" ) ytitle("结果变量Y" ) "(b)同质性处理效应路径" , pos(6)) name(TEA2)restore preserve collapse (mean ) y1 y2 y3 y0, by (treat time)tw (line y3 time if treat==2, lw(thick)) line y3 time if treat==3, lw(thick)) line y3 time if treat==4, lw(thick)) line y3 time if treat==1, lw(thick)), ylabel(0(10)30) order (1 "组群1(ATT{sub:t}=0.5t)" 2 "组群2(ATT{sub:t}=1t)" 3 "组群3(ATT{sub:t}=2t)" 4 "控制组" ) $blgd col(2)) xtitle("" ) ytitle("结果变量Y" ) "(c)异质性处理效应" , pos(6)) name(TEA3)restore gr combine TEA1 TEA2 TEA3, ysize(4) xsize(12) row(1) scale(1.5)gr export "figure/ES_TEA.png" , width(3000) replace gr export "figure/ES_TEA.svg" , replace