Science-与AI对话能持续减少阴谋论
这篇论文提出了一种新颖且有希望减少阴谋论信念的方法,显示通过与AI的个性化对话,即使是深信不疑的人也可能改变他们的信念。这一方法不同于以往悲观的观点,认为深陷阴谋论的人几乎无法改变。研究表明,设计得当的AI系统可以在改善公共讨论和应对错误信息方面发挥重要作用,前提是它们能够被负责任地使用。
标题: Durably reducing conspiracy beliefs through dialogues with AI
期刊: Science
作者:
- Thomas H. Costello:Assistant Professor of Psychology at American University. Postdoctoral fellowship at MIT (2022-2024).
- Gordon Pennycook:Himan Brown Faculty Fellow and Associate Professor of Psychology at Cornell University.
- David G. Rand:He is the Erwin H. Schell Professor and Professor of Management Science and Brain and Cognitive Sciences at MIT, the director of the Applied Cooperation Initiative, and an affiliate of the MIT Institute of Data, Systems, and Society, and the Initiative on the Digital Economy.
发布时间: 13 September 2024
引言
阴谋论的广泛性
阴谋论信念的广泛存在是一个严重的公共问题。这些信念往往涉及强大的幕后力量实施的秘密和恶意计划,虽然很多阴谋论缺乏证据甚至不合理,但依然有大量民众相信。以美国为例,过去的调查显示,多达50%的美国人相信某种形式的阴谋论。这种普遍性令人担忧,因为阴谋论被认为是对证据具有强大抗性的典型信念。
- 传统的心理学解释:阴谋论信念是通过社会心理过程产生的,削弱了人们做出理性决策和接受证据的能力。例如,人们相信阴谋论的原因可能是为了满足他们的心理需求,比如对环境控制感的渴望、寻求确定性和可预测性、保障安全感和稳定性,以及追求独特感。这些心理需求使得阴谋论不仅仅是个人的意见,更成为维持心理平衡的手段,因此很难通过证据来改变这些信念。
- 阴谋论的螺旋:许多理论假设,一旦阴谋论信念形成,尤其是当它们与个人身份或团体认同相结合时,这些信念就会变得极其顽固。人们可能会通过动机性推理的方式来处理信息,选择性忽视与其信念相悖的证据。因此,基于事实的干预往往被认为几乎无法改变阴谋论者的想法。
LLM的说服潜力
- 传统干预的问题:如果提供足够有力的个性化证据,是否有可能让阴谋论者改变他们的信念?作者认为,以往的干预尝试之所以失败,可能是因为这些干预缺乏足够的深度和针对性。阴谋论者往往拥有丰富的“证据”,他们可以运用这些证据与质疑者争辩。因此,广泛而不具体的反驳可能无法说服他们。
- AI作为解决方案:LLM具有两大优势:一是可以访问大量信息,涵盖不同主题;二是能够针对个人的具体阴谋论信念和理由进行个性化反驳。借助这种能力,LLM可以直接回应并反驳支持个人阴谋论信念的具体证据,从而克服以往反驳尝试中的难题。
实验步骤
研究参与者
目标样本:研究设定了明确的样本数量目标。通过CloudResearch的Connect参与者池进行抽样,目标是获得1000名符合条件的参与者。这些参与者是根据年龄、性别、种族和民族的美国人口普查数据进行配额匹配的,确保样本具备一定的代表性。
样本筛选:共计1214人进入了研究流程,其中有一部分参与者因为不符合特定标准而被排除。主要的排除标准包括:
- 写作质量检查:研究中引入了一个预处理写作质量检查(writing screener),以确保参与者具备良好的阅读和写作能力,且能够认真回答开放性问题。这项筛查在研究开始时进行,主要是为了排除使用自动化程序、无法理解问题或不愿认真参与的个体。
- 注意力检查:参与者还需要通过一道注意力检查题,未能通过者被移除。
- 阴谋论信念不足:那些提供的阴谋论信念不符合研究要求(即不是典型的阴谋论)或对其阴谋论信念信任度较低的参与者(信任度低于50%)也被排除。
- 对话生成的摘要不准确:如果AI生成的阴谋论摘要与参与者所表达的信念不符,该参与者的数据也会被排除。
最终,774名参与者符合条件并完成了整个实验。研究团队确保了处理前后的样本均衡性,并确认实验组和对照组之间没有显著的样本偏差。
预处理测量
阴谋论信念测量:在实验开始前,参与者需要完成一组自我报告的阴谋论信念问卷。该问卷基于修改版的Belief in Conspiracy Theories Inventory(阴谋论信念量表,简称BCTI),包括了15项广泛流行的阴谋论信念。参与者需要根据自己的信念程度为每个条目打分,分值范围为0到100,其中0表示“完全不相信”,100表示“完全相信”。平均分用于评估参与者的总体阴谋论倾向。
开放性问题:随后,参与者被要求自由描述他们相信的一个特定阴谋论,并说明支持这一信念的证据或个人经历。这一部分开放式的回答能够捕捉每个参与者的具体阴谋论信念,确保实验的个性化处理。
AI生成摘要:基于参与者对阴谋论的描述,GPT-4 Turbo生成了每个参与者信念的简短摘要,供参与者评估准确性。参与者还需要根据该摘要重新评估他们的信念强度(从0到100的评分)。
人机对话
实验组:实验组的参与者与GPT-4 Turbo进行三轮对话,AI根据参与者提供的具体阴谋论信念进行有针对性的反驳。AI被明确指示通过简单易懂的语言劝说参与者减少对阴谋论的信任度。
对照组:对照组的参与者同样与AI进行了三轮对话,但对话内容与阴谋论无关,讨论的话题可能涉及美国的医疗系统、宠物喜好(如猫狗之争)等无关主题。这种设计确保了对照组的参与者与实验组一样经历了与AI的互动,但AI并未尝试改变他们的阴谋论信念。
对话生成:实验组的AI对话是基于参与者提供的开放性阴谋论描述展开的。每个参与者的描述被送入GPT-4 Turbo,AI根据特定的提示生成反驳信息。该AI模型在实验中根据每轮对话的历史记录,逐步调整其说服策略,试图减少参与者对阴谋论的信任。
对话长度与形式:每轮对话持续大约8.4分钟,AI的回答内容丰富,通常包含多个段落,详细论述并反驳参与者的论据。对话长度控制在三轮,以平衡对话的深度与参与者的参与度。
实验后测量
阴谋论信念的再次测量:在完成对话后,参与者需要再次对其阴谋论信念的强度进行评分。该评分用于评估AI对话是否对参与者的信念产生了改变。
后续测量:实验还对参与者进行了10天和2个月后的随访,重新测量他们的阴谋论信念强度。这一随访过程用于评估AI对话效果的持久性,即信念的削弱是否能够长时间维持。
补充实验
补充实验与基础实验设计非常相似,但做了以下一些细微的调整:
- 问题措辞的调整:补充实验对阴谋论的提问方式进行了修改,避免直接问参与者是否相信某个阴谋论,而是采用更开放的方式,引导他们描述那些他们认为可信的理论。此修改旨在减少因直接提问带来的自我报告偏差。
- 禁用复制粘贴功能:为了防止参与者借助其他AI工具完成研究,实验禁用了复制粘贴功能,确保他们提供的回应是独立思考的结果。
- 行为意图测量:补充实验还新增了一些关于参与者行为意图的测量,例如他们是否愿意继续关注或取消关注发布阴谋论内容的社交媒体用户,以及他们是否愿意与阴谋论信徒进行争论。
AI对话的准确性
研究团队请专业的事实核查员对AI生成的128个陈述进行了评估。结果表明,99.2%的AI陈述是准确的,0.8%的陈述存在误导性,且没有虚假陈述。这一检查确保了AI对话的可靠性,并表明AI可以提供高质量的信息来反驳阴谋论信念。
结果
阴谋论信念的减少
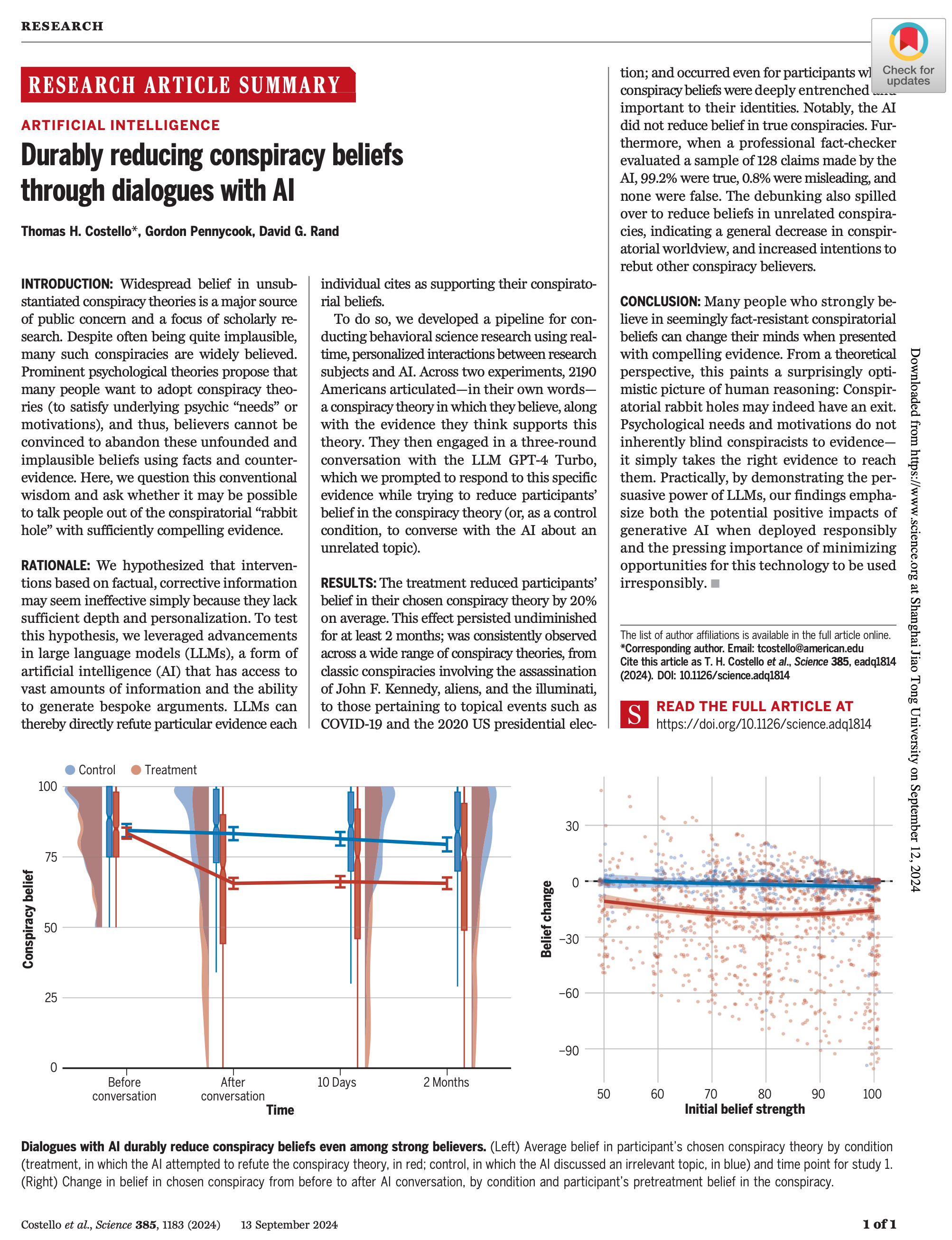
- 与AI的对话能够显著减少参与者对阴谋论的信念。实验组中,参与者的阴谋论信念平均减少了16.8分,这相当于21.43%的信念下降。而对照组的信念几乎没有改变,减少幅度仅为1.04%。
- 超过四分之一的实验组参与者(27.4%)在与AI的对话后,对自己原先坚信的阴谋论变得不确定(信念评分低于50),而对照组中只有2.4%的人发生了这种变化。
信念改变的持久性
为了验证AI对话的持久效果,研究团队在对话后的10天和2个月再次联系了参与者,重新测量他们对阴谋论的信念。
结果显示,从对话后到两个月内,阴谋论信念并未出现显著反弹,这表明AI对话的效果是持久的。这意味着,经过AI反驳后,参与者信念的变化能够在较长时间内保持稳定。
对阴谋论类型的广泛适用性
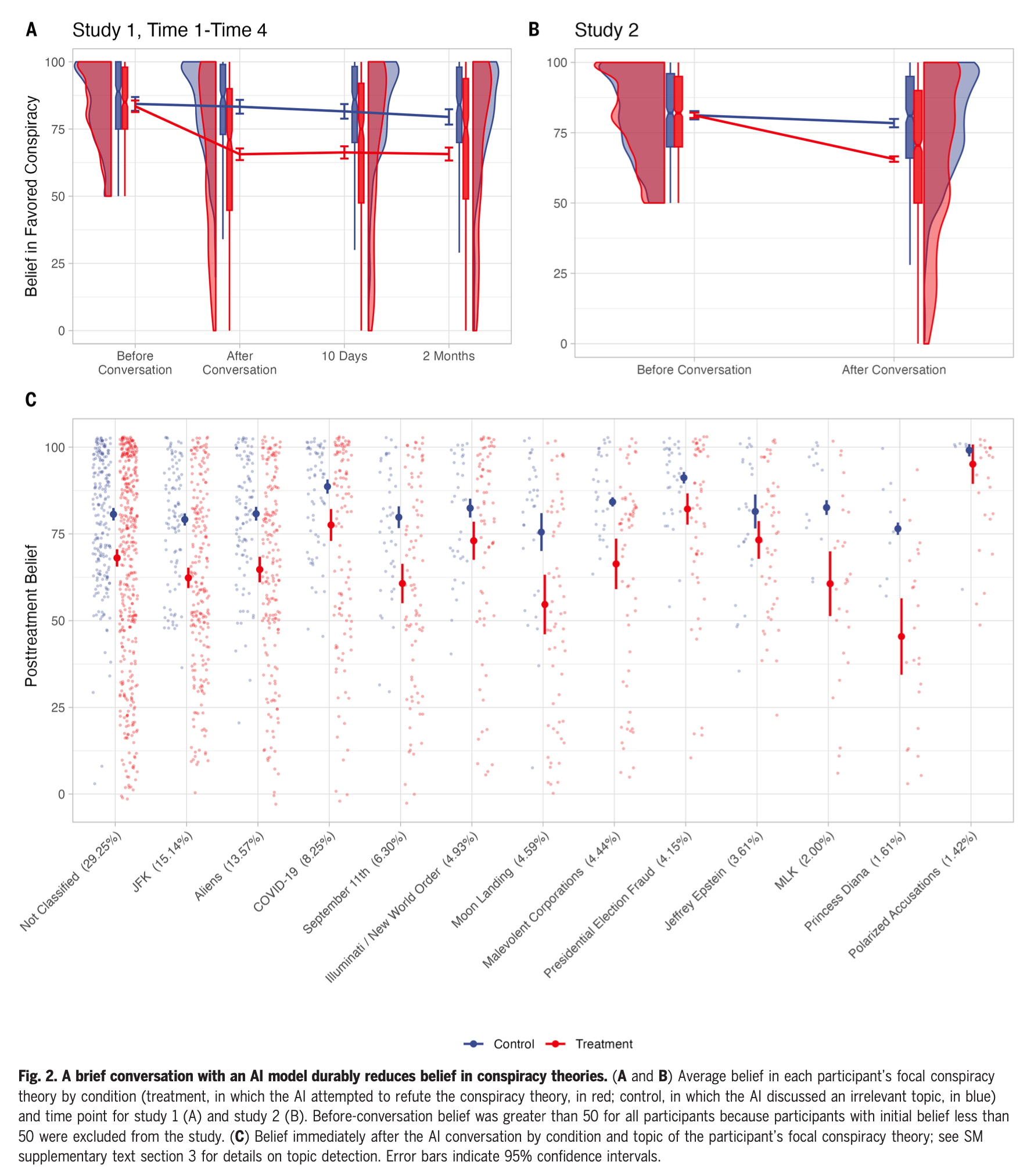
研究接着分析了AI在不同类型阴谋论上的效果。通过自然语言处理(NLP)和聚类分析,研究人员将参与者描述的阴谋论分为多个类别(如COVID-19、政治阴谋等)。
结果表明,AI反驳策略对大多数类型的阴谋论都有效,唯一例外的仅有一类阴谋论。此外,即使是高度政治化和深度根植的阴谋论(如2020年美国总统选举的舞弊指控,或COVID-19疫情相关阴谋),AI的反驳同样有效,参与者的信念显著减少。
对其他阴谋论信念的溢出效应
在这一部分,研究人员重点分析了AI对话是否不仅能减少参与者对他们选定的特定阴谋论的信念,还能削弱他们对其他阴谋论的信念。为此,研究人员使用了 Belief in Conspiracy Theories Inventory(BCTI),一个包含15种广泛阴谋论的信念量表,并通过线性混合模型分析了不同时间点的信念变化(包括对话前、对话后10天和对话后2个月的时间点)。
结果表明,在AI对话后,实验组参与者的整体阴谋论信念(即BCTI上的15个阴谋论信念评分的平均值)显著减少,减少了3.05分(约8.2%),而对照组的信念在对话后实际上增加了1.64分。这说明,AI不仅仅能减少参与者对特定阴谋论的信念,还能削弱他们对未讨论的其他阴谋论的信任。
更有力的是,这种溢出效应在两个月后的随访中仍然存在。即使考虑到参与者信念的回弹可能性,实验组在两个月后的整体阴谋论信念仍然保持下降趋势,减少了2.46分,这表明AI的干预效果具有持久性。
对高度信任阴谋论的影响
研究人员进一步分析了AI对话对参与者那些高度相信的特定阴谋论的影响,即在BCTI量表中,参与者对评分超过50(表明信念程度超过“不确定”)的阴谋论所持的态度。
结果显示,实验组对这些高度信任的阴谋论信念减少更为显著,立即减少了9.39分(约12%),相比之下,对照组的信念减少仅为3.32分。这种信念减少的效果在两个月后的随访中仍然显著(减少了5.34分),表明AI对话不仅能影响广泛的阴谋论信念,还能对那些参与者深信不疑的阴谋论产生强有力的说服作用。
行为意图的影响
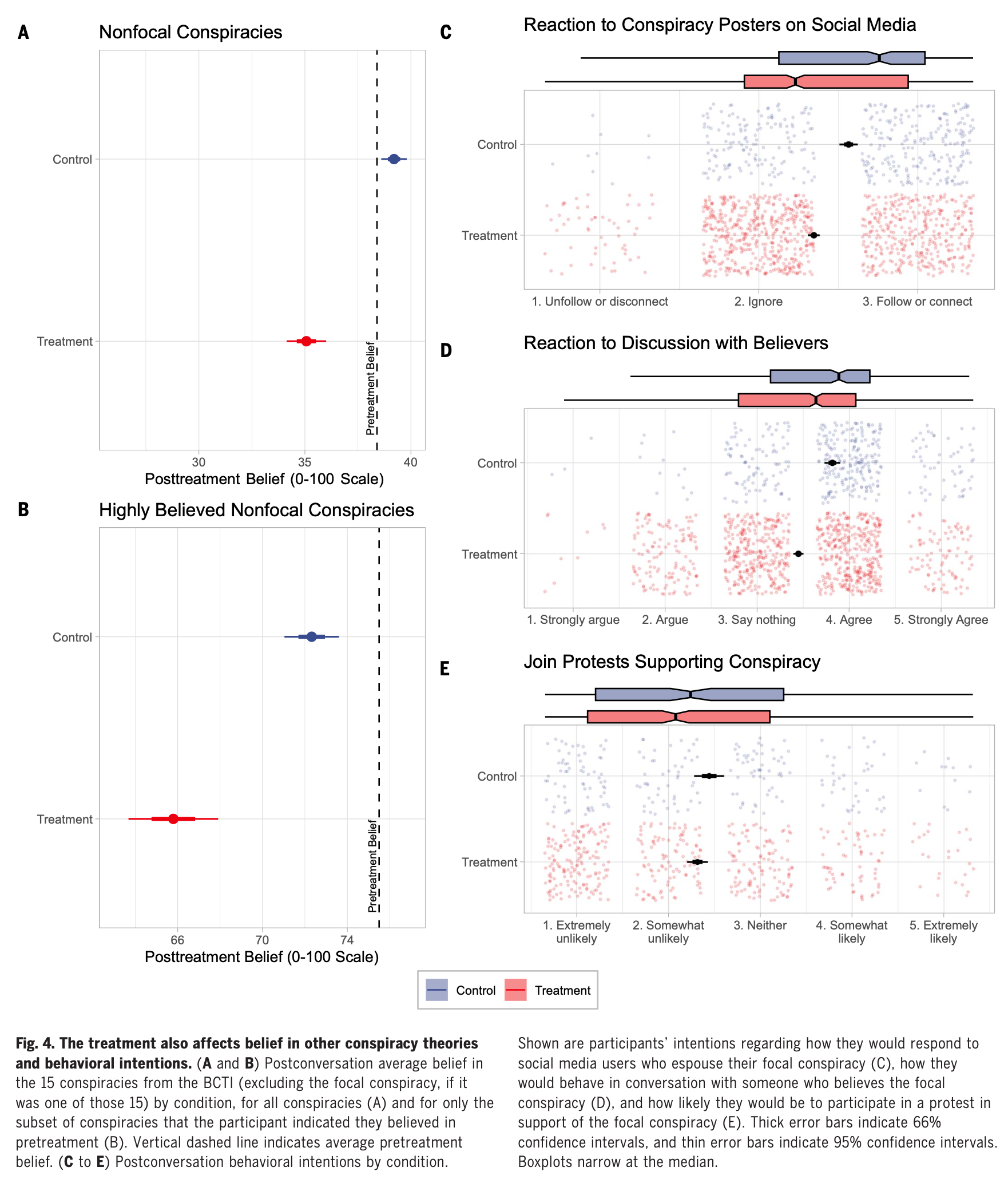
除了信念上的变化,研究还探讨了AI对话是否会改变参与者与阴谋论相关的行为意图。在补充实验中,研究团队设计了几项行为意图评估,旨在了解AI对话如何影响参与者在社交媒体、社交互动以及集体行动中的表现。
- 社交媒体行为:研究发现,AI对话显著增加了参与者在社交媒体上忽略或取消关注传播阴谋论内容的意图。实验组表示更有可能选择忽视或取消关注散布阴谋论的用户,效应值为0.39(P < 0.001)。
- 与他人的互动:参与者在面对相信阴谋论的其他人时,也表现出更高的辩论或反驳意图。AI对话显著增加了他们在与阴谋论信徒讨论时愿意反驳或忽略他们的意图,效应值为0.42(P < 0.001)。这表明AI对话不仅能够改变参与者的信念,还能激发他们在与他人互动时采取行动,来对抗阴谋论。
- 集体行动参与:关于参与者是否愿意参与支持阴谋论的集体抗议活动,研究显示AI对话对减少参与者参与此类抗议的意图有一定作用,但这个结果没有达到统计学显著性(效应值为-0.12,P = 0.12)。由于基线中支持此类行动的意图普遍较低,可能产生了地板效应,导致结果不显著。
结论与讨论
- 发现:通过与AI(GPT-4 Turbo)进行简短的个性化对话,能够显著减少参与者对阴谋论的信念。这种效果不仅限于参与者所讨论的特定阴谋论,还对其他阴谋论产生了广泛的削弱效应。此外,AI对话的效果是持久的,参与者在两个月后的信念并没有显著反弹。总体来说,AI与参与者的对话对改变阴谋论信念有着强大且持久的说服力。
- 理论推进:本研究的结果表明,尽管阴谋论信念看似顽固,但通过个性化且有针对性的对话,很多阴谋论者仍然愿意在面对足够强有力的证据时调整他们的信念。研究强调,理性思维在对抗阴谋论等非理性信念中扮演了更重要的角色,人们并非像一些理论描述的那样完全被身份认同或心理动机所束缚,而是能够在面对具有说服力的论据时改变信念。
- 局限:样本的代表性:研究主要依赖于美国的在线调查参与者,这些人通常是为了物质报酬而参与调查。因此,未来的研究需要进一步验证这些结果是否可以推广到更广泛的社会群体,尤其是那些未参与过学术研究或活跃于阴谋论社区的个体。AI模型的限制:研究使用了最新的GPT-4 Turbo模型,这一模型是闭源的,并经过专门的微调,因此其他语言模型是否也能产生类似效果尚不清楚。研究结果的有效性可能依赖于这一模型的特殊性,未来研究需要检验其他模型的表现。潜在的机制分析:虽然研究证明了AI对话能够显著减少阴谋论信念,但具体的心理或认知机制尚未明确。这是因为每个对话都是独特的,包含理性论证和社会线索的混合。未来研究应深入分析AI在对话中采用的具体策略,以及这些策略如何影响参与者的信念改变。
号外
这篇论文从投稿到接收仅用时两个多月(Submitted 1 May 2024; accepted 18 July 2024);
这篇推文是GPT-4o撰写的,请谨慎对待推文的内容!⚠️
大语言模型常常因为其在回答中杜撰事实被人诟病,而这篇论文却发现其在说服方面具有意外效果,是非常有趣的研究!
上周的推文被微信ban了,而我又不愿意在语言和文字上练习“葵花宝典”,所以没有发出来,不是我拖延。有兴趣的小伙伴自行查看论文吧(Playing the sycophant card: The logic and consequences of professing loyalty to the autocrat),或者在我的博客可以找到。
原文信息
Costello, Thomas H., Gordon Pennycook, and David G. Rand. "Durably reducing conspiracy beliefs through dialogues with AI." Science 385, no. 6714 (2024): eadq1814. https://www.science.org/doi/10.1126/science.adq1814