任务可验证性影响我们会不会被AI替代
人工智能(AI)将如何重塑劳动力市场?现有研究主要通过任务内容(如常规性)或技术暴露度来预测AI的影响。本文认为,这些框架忽略了一个更根本的机制:任务的可验证性(verifiability)。借鉴基于强化学习思想的验证器定律(Verifier's Law),我提出,一项任务被AI自动化的速度和深度,与其产出能否被客观、快速、可扩展地验证高度相关。为将此理论框架操作化,我基于O*NET数据库,构建了暴露度-可验证性二维四象限框架,用以分析不同职业群体面临的差异化自动化路径。本文的研究为理解AI对劳动力市场差异化影响的微观基础提供了新的理论视角。
生成式人工智能正在颠覆一个古老的不对称性:在人类历史的绝大部分时间里,创造比评判更难,写一部小说比评价它更难,证明一个定理比检验它更难,制定一项战略比事后评估它更难。人工智能正在逆转这一关系。当生成变得廉价甚至免费,验证就成为真正的瓶颈。
生成式AI在不同职业领域的渗透速度和深度存在显著差异。软件工程领域,AI编码助手已经深度嵌入开发流程,代码生成、测试、调试等环节的自动化程度不断提高,程序员的角色正在快速转变。与此同时,战略咨询、公共关系、心理治疗等同样高度依赖语言和认知的领域,AI更多只是扮演辅助角色。这种差异无法简单地用任务复杂性来解释,因为编程和战略咨询的复杂性并无明确的高低之分。
这种分化的背后存在一个被劳动经济学研究长期忽视的机制:评价与纠错能否被规模化地制度化。 本文将这种差异概括为任务的可验证性,并尝试将其操作化为一个可度量的指标。
验证器定律
理解这一机制需要回到AI能力如何演化的技术本源。Jason Wei(2024)提出的"验证器定律"(Verifier's Law)指出:AI在某个任务上能力提升的速度,与该任务的产出能否被廉价、快速、可扩展地验证成正比。
其核心逻辑在于AI模型的进步依赖一个“生成、检验、改进”的迭代循环(即强化学习的基本思想)。模型生成输出,验证器评估好坏,模型据此调整参数。这个循环的效率完全取决于验证器的质量和成本。在形式上,这可以被表述为一个简洁的命题:给定一个充分好的验证器(verifier),AI在对应任务上的能力将快速收敛到人类水平乃至超越人类水平;缺乏验证器的任务则构成AI能力扩展的结构性瓶颈。
AlphaGo在围棋上超越所有人类棋手,根本原因在于围棋拥有完美的验证器:规则明确定义了胜负,判定瞬间完成,成本为零,AlphaGo因此可以通过数百万次自我对弈快速迭代。代码生成领域AI进步同样飞速,因为编译器和单元测试构成了廉价的自动化验证系统,代码要么跑通,要么报错,反馈即时而清晰。数学证明的情况类似:证明的每一步都可以被形式化检验,Lean等证明辅助工具(proof assistant)使AI能够在高度确定的反馈回路中训练。这些领域的共同特征是:验证成本趋近于零,验证速度趋近于即时,验证结果高度客观。
相比之下,企业战略的优劣可能需要数年才能显现,其间充满市场环境、竞争对手行为等混杂因素。心理咨询的效果取决于来访者内在体验的改善,这一过程高度个人化,难以标准化评估。这些领域不是AI尚未足够聪明,而是在本体论层面就不存在可被算法捕捉的单一正确答案。战略决策、价值判断、美学品味、伦理权衡的正确性由人类社会的共识、文化和权力关系所建构。这构成了AI能力的一个结构性边界。
这一原理具有普遍性。它解释了为什么存在AlphaGo却不可能有AlphaStrategist,也预测了AI能力扩展的边界不由算力或数据量决定,而由任务环境的反馈结构决定。
现有研究
理解了验证器定律,便可看到现有AI劳动力市场研究的一个关键局限。
Eloundou等人(2024)在Science上发表的GPTs are GPTs是这一领域的里程碑。研究评估了O*NET数据库中每一项职业任务被LLM影响的程度,构建了LLM暴露度指标,发现约80%的美国劳动力至少有10%的任务会受到影响,且高收入白领职业暴露度更高。更早的工作中,Frey and Osborne(2017)预测47%的美国就业岗位面临高自动化风险,Autor, Levy and Murnane(2003)建立了用常规/非常规划分理解技术替代的经典框架。
这些工作提供了宝贵的见解,但共享一个隐含假设:将AI视为一种能力边界固定的工具。 测量AI能做什么,测量职业需要什么,两者重叠即为暴露。然而,当代AI最本质的特征在于它是一个能够自我进化的学习系统。暴露度衡量的是AI在某个时间截面的能力,却未能回答一个更重要的动态问题:AI在哪些任务上会快速突破,又在哪些任务上会持续受阻?
可验证性正是回答这一问题的关键变量。它不衡量AI当前的能力,而是预测AI能力的增长速度和天花板。高可验证性领域(数学证明、代码生成、棋类博弈)是AI能力指数级增长的快车道。低可验证性领域(战略咨询、心理治疗、艺术创作)是AI能力增长的减速带,原因不在于任务本身困难,而在于缺乏足够好的反馈信号来驱动学习循环。
将暴露度与可验证性结合,便产生了一个更完整的分析框架:暴露度回答"AI现在能做什么",可验证性回答"AI将以多快的速度做得更好"。两者的交叉定义了四种截然不同的职业命运。
TVI指数的构建
为将上述理论框架操作化,本研究构建了任务可验证性指数(Task Verifiability Index, TVI),将任务的可验证性分解为五个维度:
- 客观性(Objectivity):是否存在独立于主观偏好的质量标准。数学计算有唯一正确答案(5分),诗歌的艺术价值则没有(1分)。
- 速度(Velocity):完成一次验证所需的时间。代码编译的反馈是秒级的(5分),基础研究的价值可能需要数年验证(1分)。
- 可扩展性(Scalability):验证过程能否低成本地大规模自动化。单元测试可以无限扩展(5分),专家评审无法规模化(1分)。
- 信噪比(Signal-to-Noise Ratio):验证信号在多大程度上反映真实质量。棋局的胜负完美反映棋力(5分),销售额反映销售策略的效果但受市场环境等噪声干扰(3分)。
- 反馈密度(Feedback Density):任务执行过程中获得反馈的频率。导航系统提供持续修正(5分),小说写作可能只在完稿后获得系统性反馈(1分)。
每个维度按1-5分评估。评分对象是O*NET数据库中每个职业包含的具体任务描述(Detailed Work Activities),这也是Eloundou等人(2024)构建暴露度指标时所使用的同一套任务集。本研究使用GPT 5.2对每一项任务进行五维度评分。选择LLM而非人类标注的原因在于规模:数据库包含数千项任务,每项需要在五个维度上独立评分,且需要覆盖从外科手术到金融分析到幼儿教育的跨领域专业知识。Eloundou等人(2024)的研究本身也表明,GPT-4的任务标注与人类标注之间具有较高的一致性。
按照与GPTs are GPTs一致的权重方案(核心任务权重1.0,补充任务权重0.5),任务层面TVI被加总到职业层面,最终覆盖923个美国职业。
分析框架
将TVI与LLM暴露度置于同一坐标系中,923个职业自然分布在四个象限内(以各自中位数为分界),每个象限对应一种独特的AI影响模式。
图1:任务可验证性 vs LLM暴露度(923个美国职业)
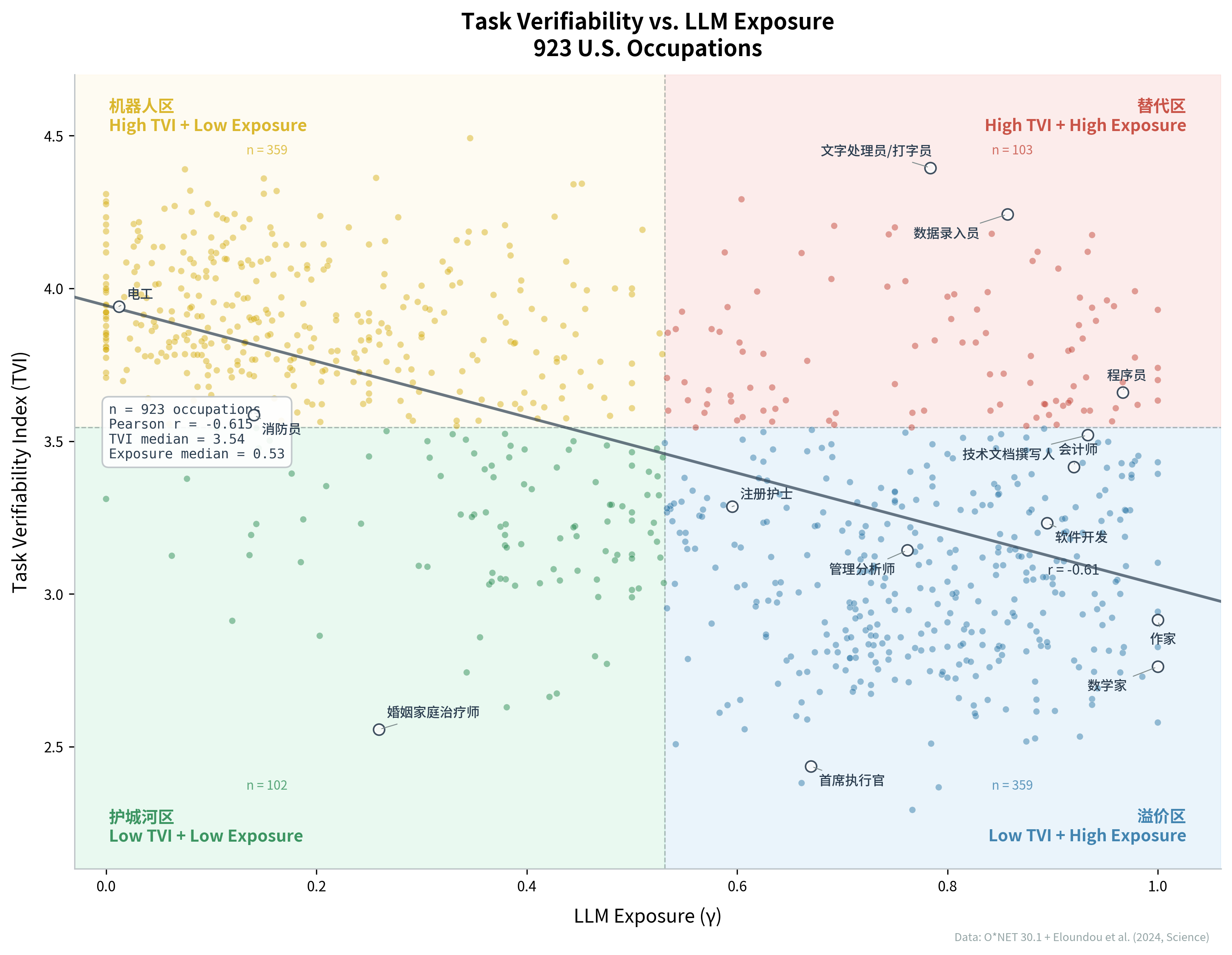
替代区(高可验证性 + 高暴露度,103个职业)
典型代表包括文字处理员与打字员(TVI = 4.28, E = 0.94)、数据录入员(TVI = 4.12, E = 0.91)、税务申报员(TVI = 3.63, E = 1.00),以及程序员(TVI = 3.66, E = 0.97)和网络系统管理员(TVI = 3.62, E = 0.89)。这些职业的共同特征是:任务产出既适合LLM处理,又可以通过程序化手段进行验证。文档是否准确转录了原始信息、数据是否正确录入系统、代码是否通过了测试,这些问题都有客观的对错标准。这是AI最容易从"辅助工具"升级为"自主系统"的领域,端到端自动化的技术条件和组织条件最为成熟。
值得注意的是,O*NET对"计算机与软件"类职业的细分揭示了一个有意义的区别。"Computer Programmers"(程序员,15-1251)的TVI为3.66,落在替代区,因为编程任务的核心产出(代码)可以被编译器、测试套件和静态分析工具自动验证。而"Software Developers"(软件开发,15-1252)的TVI仅为3.23,落在溢价区,因为软件开发的核心任务包含了架构设计、需求分析、技术选型等验证成本显著更高的环节。同一个行业的两种角色,因为任务可验证性的差异,面临着截然不同的自动化前景。这一区分不仅验证了TVI框架的分辨力,也为理解技术行业内部的分化提供了一个精确的切入点。
溢价区(低可验证性 + 高暴露度,359个职业)
管理分析师(TVI = 3.10, E = 0.90)、金融量化分析师(TVI = 2.92, E = 1.00)、作家(TVI = 3.06, E = 0.93)、视频游戏设计师(TVI = 2.94, E = 1.00)、首席执行官(TVI = 2.44, E = 0.67)等大量知识工作者集中在这里。这是四个象限中规模最大的一个,也是理解AI时代劳动力市场变革的关键。LLM在此类职业中是强大的生产力工具,能够快速生成报告初稿、备选方案和数据分析,但这些产出的质量很难通过自动化手段验证。战略建议的优劣可能数年后才能验证,分析报告的判断是否准确受大量外部因素干扰。在现行经济和法律体系中,AI尚未作为最终责任人出现,组织无法将最终决策权完全让渡给AI。因此,这个象限将出现显著的"验证者溢价"(verifier premium):当生成变得廉价后,能够判断产出质量好坏的人类判断力反而变得更加稀缺和有价值。
机器人区(高可验证性 + 低暴露度,359个职业)
包装机操作员(TVI = 4.39, E = 0.08)、邮件分拣员(TVI = 4.36, E = 0.15)、电工(TVI = 3.73, E = 0.44)等。这些职业的产出验证标准客观清晰(产品是否合格、线路是否正确、设备是否运转),但核心瓶颈在于物理操作,LLM无法触及。此领域面临传统自动化和具身智能的长期替代压力,时间线更长,但替代一旦实现可能更为彻底。自工业革命以来,物理任务的自动化已持续两个多世纪(Autor, Levy and Murnane, 2003),LLM的出现并未加速这一进程。
护城河区(低可验证性 + 低暴露度,102个职业)
婚姻家庭治疗师(TVI = 2.56, E = 0.26)、牧师(TVI = 2.63, E = 0.38)、心理健康咨询师(TVI = 2.66, E = 0.42)等。这些职业的任务既不以文本信息处理为核心,其服务质量的评估也高度主观化和情境化。心理治疗是否有效、一场宗教仪式是否有感染力,这些评价依赖于人与人之间不可还原的互动体验。AI在此领域短期内几乎没有直接替代的可能,渗透更多通过排班优化、信息检索等外围工具间接发生。
图2:各职业大类的平均TVI与LLM暴露度
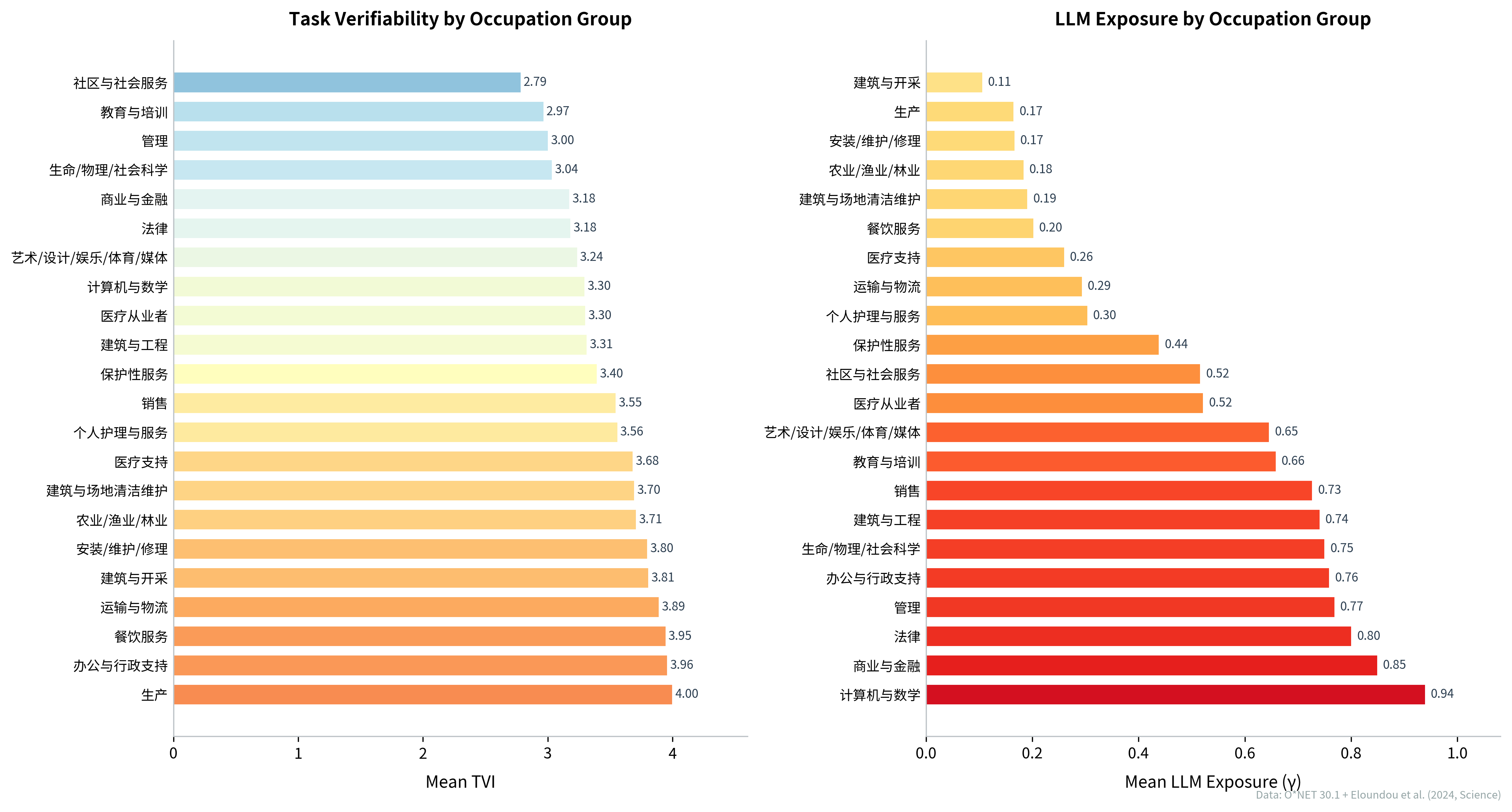
从职业大类的视角来看,"计算机与数学"类LLM暴露度最高(0.94),TVI为中等偏低(3.30),主要落在溢价区和替代区之间;"商业与金融"类暴露度同样很高(0.85),TVI也偏低(3.18),是溢价区的核心地带。"生产"和"建筑与开采"类的TVI最高(4.00和3.81),暴露度最低(0.17和0.11),是典型的机器人区。认知密集型行业和物理操作型行业在这两个维度上形成清晰的镜像分布。值得关注的是"社区与社会服务"类(TVI = 2.79, E = 0.52),它的TVI在所有大类中最低,直观反映了人际服务的评估困难。
对劳动力市场的含义
生成式AI的扩散正在沿着可验证性这一维度,制造一种新的职业分化。在高可验证性领域,AI正快速从辅助角色转向自主执行;在低可验证性领域,AI虽然被广泛使用,但长期停留在"副驾驶"位置。
自工业革命以来,工人的角色不断从执行任务转向监督任务(Autor et al.,2003)。工厂自动化使人类从体力劳动转向生产监督,会计软件使专业人士从原始计算转向策略识别。在这两种情况下,人类始终对最终产品的质量负责,识别和修复错误的技术知识依然不可或缺。生成式AI正在以前所未有的规模和速度延续这一历史模式。
这一分析引出若干具体的政策和组织层面的命题。
验证基础设施是自动化的前提条件。 企业推进自动化的关键工作,往往不是引入更强大的模型,而是构建可验证的流程环境:标准化操作规程、测试用例体系和数据质量管控。一家律所引入AI辅助起草合同的成效,更多取决于其合规审查流程的成熟度,而非AI模型本身的语言能力。验证体系与审计机制本身构成一种基础设施,决定了模型输出能否转化为可靠的生产要素。
人力资本的价值正在重新配置。 在溢价区,"能生成"的技能被AI压缩,"能判断"的技能被放大。初级分析师撰写研报的能力正在贬值,而资深分析师识别框架缺陷的能力正在升值。这一趋势将压缩部分知识劳动的入门路径,同时提高"验证型"专家的溢价。
公共政策的着力点在于提升社会的验证供给能力。 标准制定、评估工具、责任规则与审计人才培训,这些看似技术性的"基础设施"投入,实际上决定了AI在哪些领域能够安全地深入部署。医疗领域AI应用的进展,在很大程度上取决于临床试验、伦理审查和监管审批等验证制度的成熟与适配。
波兰尼(Polanyi)的"隐性知识"(tacit knowledge)概念在这一语境下获得了新的意义。那些难以被编纂化(codified)的知识,即经验判断、情境直觉、对"什么是好的"的内隐感知,恰恰是低可验证性领域的核心要素,也是当前AI最难以习得的能力。未来职业分化的主轴,很可能越来越多地围绕可验证性展开。
号外
- 这篇文章是我看到Jason Wei博客后想到的,做了好久,感觉不能拖了,先搓一个推文吧;文本是AI生成的,请注意幻觉问题;
- 如果您有任何意见/建议,请留言或私信;
- 最近半年常常有很强的无意义感,文科在强AI面前,除了抓紧机会多水几篇论文和卖课之外,还能做什么?
参考文献
Acemoglu, D. (2025). The Simple Macroeconomics of AI. NBER Working Paper, 32487.
Autor, D. H., Levy, F., & Murnane, R. J. (2003). The Skill Content of Recent Technological Change: An Empirical Exploration. The Quarterly Journal of Economics, 118(4), 1279–1333.
Brynjolfsson, E., & Mitchell, T. (2017). What can machine learning do? Workforce implications. Science, 358(6370), 1530–1534.
Eloundou, T., Manning, S., Mishkin, P., & Rock, D. (2024). GPTs are GPTs: Labor market impact potential of LLMs. Science, 384, 1306–1308.
Frey, C. B., & Osborne, M. A. (2017). The future of employment: How susceptible are jobs to computerisation? Technological Forecasting and Social Change, 114, 254–280.
Polanyi, M. (1966). The Tacit Dimension. University of Chicago Press.
Wei, J. (2024). Asymmetry of verification and verifier's law. Jason Wei's Blog.